How to add an aggregate function?¶
Aggregate functions are calculated by the HashAggregation operator. There can be one or more aggregate functions in a single operator. Here are some examples.
Global aggregation (no grouping keys), single aggregate “count”.
SELECT count(*) FROM t
Global aggregation, two aggregates: “count” and “sum”:
SELECT count(*), sum(b) FROM t
Aggregation with three aggregates: “count” and two “sum”s.
SELECT a, count(*), sum(b), sum(c) FROM t GROUP BY 1
Aggregation with just one aggregate - “min” - and two grouping keys.
SELECT a, b, min(c) FROM t GROUP BY 1, 2
Typically, aggregations are calculated in two steps: partial aggregation and final aggregation.
Partial aggregation takes raw data and produces intermediate results. Final aggregation takes intermediate results and produces the final result. There are also single and intermediate aggregations that are used in some cases. Single aggregation is used when data is already partitioned on the grouping keys and therefore no shuffle is necessary. Intermediate aggregations are used to combine the results of partial aggregations computed in multiple threads in parallel to reduce the amount of data sent to the final aggregation stage.
The four types, steps, of aggregation are distinguished solely by the types of input and output.
Step |
Input |
Output |
|---|---|---|
Partial |
Raw Data |
Intermediate Results |
Final |
Intermediate Results |
Final Results |
Single |
Raw Data |
Final Results |
Intermediate |
Intermediate Results |
Intermediate Results |
In some cases, the calculations performed by partial and final aggregations are
the same. This is the case for the sum(), min() and max()
aggregates. In most cases they are different. For example, partial count()
aggregate counts incoming values and final count() aggregate sums up partial
counts to produce a total.
The signature of an aggregate function consists of the type of the raw input data, the type of the intermediate result and the type of the final result.
Aggregate functions can also be used in a window operator. Here is an example of
computing running total that uses sum() aggregate function in a window operator.
SELECT a, sum(b) OVER (PARTITION by c ORDER BY d DESC) FROM t
Memory Layout¶
HashAggregation operator stores data in rows. Each row corresponds to a unique combination of grouping key values. Global aggregations store data in a single row.
Aggregate functions can be classified by the type of their accumulators into three groups:
- Variable width accumulators with append-only semantics:
- Variable width accumulators which can be modified in any way, not just appended to.
arbitrary()(for variable-width types)
Fixed-width part of the accumulator is stored in the row. Variable-width part (if exists) is allocated using HashStringAllocator and a pointer is stored in the fixed-width part.
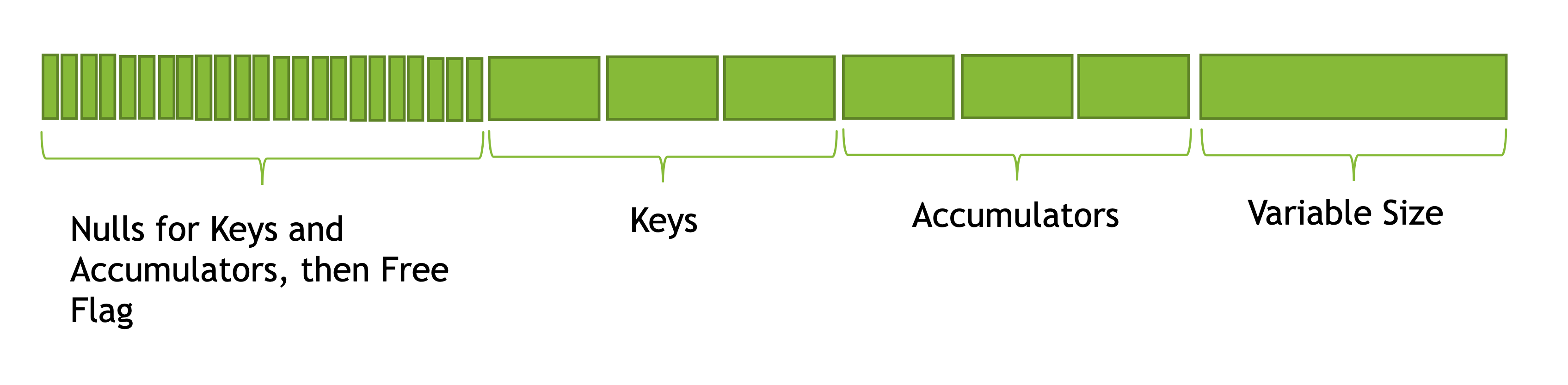
A row is a contiguous byte buffer. If any of the accumulators has alignment requirement, the row beginning and accumulator address will be aligned accordingly. Data is stored in the following order:
- Null flags (1 bit per item) for
Keys (only if nullable)
Accumulators
Free flag (1 bit)
Keys
Padding for alignment
Accumulators, fixed-width part only
Variable size (32 bit)
Padding for alignment
To add an aggregate function, there are two options: implementing it as a simple function or as a vector function. The simple-function interface allows the author to write methods that process input data one row at a time and not handle input vector encodings themselves. However, the simple-function interface currently has certain limitations, such as not allowing for advanced performance optimization on constant inputs. Aggregation functions that require such functionalities can be implemented through the vector-function interface. With the vector-function interface, the author writes methods that process one vector at a time and handles input vector encodings by themselves.
- Prepare:
Figure out what are the input, intermediate and final types.
Figure out what are partial and final calculations.
Design the accumulator. Make sure the same accumulator can accept both raw inputs and intermediate results.
If implementing a simple function, create a class for the function according to instructions below; If implementing a vector function, create a new class that extends velox::exec::Aggregate base class (see velox/exec/Aggregate.h) and implement virtual methods.
Register the new function using exec::registerAggregateFunction(…).
Add tests.
Write documentation.
Simple Function Interface¶
This section describes the main concepts and the simple interface of aggregation functions. Examples of aggregation functions implemented through the simple-function interface can be found at SimpleAverageAggregate.cpp, SimpleArrayAggAggregate.cpp, SimpleVariadicSumAggregate.cpp, and SimpleVariadicArrayAggAggregate.cpp under velox/exec/tests.
A simple aggregation function is implemented as a class as the following.
// array_agg(T) -> array(T) -> array(T)
class ArrayAggAggregate {
public:
// Type(s) of input vector(s) wrapped in Row.
using InputType = Row<Generic<T1>>;
using IntermediateType = Array<Generic<T1>>;
using OutputType = Array<Generic<T1>>;
// Optional. Default is true.
static constexpr bool default_null_behavior_ = false;
// Optional.
static bool toIntermediate(
exec::out_type<Array<Generic<T1>>>& out,
exec::optional_arg_type<Generic<T1>> in);
// Optional. Define some function-level variables.
TypePtr inputType_;
TypePtr resultType_;
// Optional. Defined only when the aggregation function needs to use function-level variables.
// This method is called once when the aggregation function is created.
void initialize(
core::AggregationNode::Step step,
const std::vector<TypePtr>& argTypes,
const TypePtr& resultType) {
VELOX_CHECK_EQ(argTypes.size(), 1);
inputType_ = argTypes[0];
resultType_ = resultType;
}
// Optional. Defined only when the aggregation function needs to access constant arguments.
// This method is called once after the aggregation function is created, before any data
// is processed. Non-constant inputs have null entries in constantInputs.
void setConstantInputs(const std::vector<VectorPtr>& constantInputs) {
// Example: Extract a constant boolean flag from the second argument
if (constantInputs.size() >= 2 && constantInputs[1] != nullptr) {
ignoreNulls_ = constantInputs[1]->as<ConstantVector<bool>>()->valueAt(0);
}
}
struct AccumulatorType { ... };
};
The author declares the function’s input type, intermediate type, and output type in the simple aggregation function class. The input type must be the function’s argument type(s) wrapped in a Row<> even if the function only takes one argument. This is needed for the SimpleAggregateAdapter to parse input types for arbitrary aggregation functions properly.
The author can optionally define function-level variables in the simple aggregation function class. These variables are initialized once when the aggregation function is created and used at every row when adding inputs to accumulators or extracting values from accumulators. For example, if the aggregation function needs to get the result type or the raw input type of the aggregation function, these types can be defined as member variables in the aggregate class and initialized in the initialize() method.
The author can also optionally define a setConstantInputs() method to access constant arguments at initialization time. This method is called once after the aggregation function is created, before any data is processed. The method receives a vector of constant input values, where non-constant inputs have null entries. This is useful for reading configuration flags or constant parameters that don’t change during aggregation. For example, a function might use this to read a boolean flag that controls null handling behavior.
The author can define an optional flag default_null_behavior_ indicating whether the aggregation function has default-null behavior. This flag is true by default. Next, the class can have an optional method toIntermediate() that converts the aggregation function’s raw input directly to its intermediate states. Finally, the author must define a struct named AccumulatorType in the aggregation function class. We explain each part in more details below.
Default-Null Behavior¶
When adding raw inputs or intermediate states to accumulators, aggregation functions of default-null behavior ignore the input values that are nulls. For raw inputs that consist of multiple columns, an entire row is ignored if at least one column is null at this row. Below is an example.
SELECT sum(c0) FROM (values (cast(NULL as bigint), 10), (NULL, 20), (NULL, 30)) AS t(c0, c1); -- NULL
When generating intermediate or final output results from accumulators, aggregation functions of default-null behavior produce nulls for groups of no input row or only null rows. Another example is given below.
SELECT sum(c0) FROM (values (1, 10), (2, 20), (3, 30)) AS t(c0, c1) WHERE c1 > 40; -- NULL
Most aggregation functions have default-null behavior. An example is in SimpleAverageAggregate.cpp. On the other hand, SimpleArrayAggAggregate.cpp has an example of non-default-null behavior.
This flag affects the C++ function signatures of toIntermediate() and methods in the AccumulatorType struct.
toIntermediate¶
The author can optionally define a static method toIntermediate() that converts a raw input to an intermediate state. If defined, this function is used in query plans that abandon the partial aggregation step. If the aggregation function has default-null behavior, the toIntermediate() function has an out-parameter of the type exec::out_type<IntermediateType>& followed by in-parameters of the type exec::arg_type<T> for each T wrapped inside InputType . If the aggregation function has non-default null behavior, the in-parameters of toIntermediate() are of the type exec::optional_arg_type<T> instead.
When T is a primitive type except Varchar and Varbinary, exec::arg_type<T> is simply T itself and exec::out_type<T> is T&. exec::optional_arg_type<T> is std::optional<T>.
When T is Varchar, Varbinary, or a complex type, exec::arg_type<T>, exec::optional_arg_type<T>, and exec::out_type<T> are the corresponding view and writer types of T. A detailed explanation can be found in View and Writer Types.
Default-Null Behavior |
Non-Default-Null Behavior |
|---|---|
|
|
AccumulatorType of Default-Null Behavior¶
For aggregaiton functions of default-null behavior, the author defines an AccumulatorType struct as follows.
struct AccumulatorType {
// Author defines data members
...
// Optional. Define a pointer to the UDAF class if the aggregation
// function uses function-level variables.
ArrayAggAggregate* fn_;
// Optional. Default is true.
static constexpr bool is_fixed_size_ = false;
// Optional. Default is false.
static constexpr bool use_external_memory_ = true;
// Optional. Default is false.
static constexpr bool is_aligned_ = true;
explicit AccumulatorType(
HashStringAllocator* allocator, ArrayAggAggregate* fn)
: fn_(fn);
void addInput(HashStringAllocator* allocator, exec::arg_type<T1> value1, ...);
void combine(
HashStringAllocator* allocator,
exec::arg_type<IntermediateType> other);
bool writeIntermediateResult(exec::out_type<IntermediateType>& out);
bool writeFinalResult(exec::out_type<OutputType>& out);
// Optional. Called during destruction.
void destroy(HashStringAllocator* allocator);
};
The author defines an optional flag is_fixed_size_ indicating whether the every accumulator takes fixed amount of memory. This flag is true by default. Next, the author defines another optional flag use_external_memory_ indicating whether the accumulator uses memory that is not tracked by Velox. This flag is false by default. Then, the author can define an optional flag is_aligned_ indicating whether the accumulator requires aligned access. This flag is false by default.
The author defines a constructor that takes a single argument of HashStringAllocator*. This constructor is called before aggregation starts to initialize all accumulators.
The author can also optionally define a destroy function that is called when this accumulator object is destructed.
Notice that writeIntermediateResult and writeFinalResult are expected to not modify contents in the accumulator.
addInput¶
This method adds raw input values to this accumulator. It receives a HashStringAllocator* followed by exec::arg_type<T1>-typed values, one for each argument type Ti wrapped in InputType.
With default-null behavior, raw-input rows where at least one column is null are ignored before addInput is called. After addInput is called, this accumulator is assumed to be non-null.
combine¶
This method adds an input intermediate state to this accumulator. It receives a HashStringAllocator* and one exec::arg_type<IntermediateType> value. With default-null behavior, nulls among the input intermediate states are ignored before combine is called. After combine is called, this accumulator is assumed to be non-null.
writeIntermediateResult¶
This method writes this accumulator out to an intermediate state vector. It has an out-parameter of the type exec::out_type<IntermediateType>&. This method returns true if it writes a non-null value to out, or returns false meaning a null should be written to the intermediate state vector. Accumulators that are nulls (i.e., no value has been added to them) automatically become nulls in the intermediate state vector without writeIntermediateResult being called.
writeFinalResult¶
This method writes this accumulator out to a final result vector. It has an out-parameter of the type exec::out_type<OutputType>&. This method returns true if it writes a non-null value to out, or returns false meaning a null should be written to the final result vector. Accumulators that are nulls (i.e., no value has been added to them) automatically become nulls in the final result vector without writeFinalResult being called.
AccumulatorType of Non-Default-Null Behavior¶
For aggregaiton functions of non-default-null behavior, the author defines an AccumulatorType struct as follows.
struct AccumulatorType {
// Author defines data members
...
// Optional. Default is true.
static constexpr bool is_fixed_size_ = false;
// Optional. Default is false.
static constexpr bool use_external_memory_ = true;
// Optional. Default is false.
static constexpr bool is_aligned_ = true;
explicit AccumulatorType(HashStringAllocator* allocator, ArrayAggAggregate* fn);
bool addInput(HashStringAllocator* allocator, exec::optional_arg_type<T1> value1, ...);
bool combine(
HashStringAllocator* allocator,
exec::optional_arg_type<IntermediateType> other);
bool writeIntermediateResult(bool nonNullGroup, exec::out_type<IntermediateType>& out);
bool writeFinalResult(bool nonNullGroup, exec::out_type<OutputType>& out);
// Optional.
void destroy(HashStringAllocator* allocator);
};
The definition of is_fixed_size_, use_external_memory_, is_aligned_, the constructor, and the destroy method are exactly the same as those for default-null behavior.
On the other hand, the C++ function signatures of addInput, combine, writeIntermediateResult, and writeFinalResult are different.
Same as the case for default-null behavior, writeIntermediateResult and writeFinalResult are expected to not modify contents in the accumulator.
addInput¶
This method receives a HashStringAllocator* followed by exec::optional_arg_type<T1> values, one for each argument type Ti wrapped in InputType.
This method is called on all raw-input rows even if some columns may be null. It returns a boolean meaning whether this accumulator is non-null after the call. All accumulators are initialized to null before aggregation starts. An accumulator that is originally null can be turned to non-null. But an accumulator that’s already non-null remains non-null regardless of the return value of addInput.
combine¶
This method receives a HashStringAllocator* and an exec::optional_arg_type<IntermediateType> value. This method is called on all intermediate states even if some are nulls. Same as addInput, this method returns a boolean meaning whether this accumulator is non-null after the call.
writeIntermediateResult¶
This method has an out-parameter of the type exec::out_type<IntermediateType>& and a boolean flag nonNullGroup indicating whether this accumulator is non-null. This method returns true if it writes a non-null value to out, or return false meaning a null should be written to the intermediate state vector.
writeFinalResult¶
This method writes this accumulator out to a final result vector. It has an out-parameter of the type exec::out_type<OutputType>& and a boolean flag nonNullGroup indicating whether this accumulator is non-null. This method returns true if it writes a non-null value to out, or return false meaning a null should be written to the final result vector.
Limitations¶
The simple aggregation function interface currently has one limitation: aggregation pushdown to table scan is not supported yet. We’re planning to add this support.
Vector Function Interface¶
Aggregation functions that cannot use the simple-function interface can be written as vector funcitons.
Accumulator size¶
The implementation of the velox::exec::Aggregate interface can start with accumulatorFixedWidthSize() method.
// Returns the fixed number of bytes the accumulator takes on a group
// row. Variable width accumulators will reference the variable
// width part of the state from the fixed part.
virtual int32_t accumulatorFixedWidthSize() const = 0;
If accumulator requires specific alignment you need to implement accumulatorAlignmentSize() method.
/// Returns the alignment size of the accumulator. Some types such as
/// int128_t require aligned access. This value must be a power of 2.
virtual int32_t accumulatorAlignmentSize() const {
return 1;
}
The HashAggregation operator uses these methods during initialization to calculate the total size of the row and figure out offsets at which different aggregates will be storing their data. The operator then calls velox::exec::Aggregate::setOffsets method for each aggregate to specify the location of the accumulator.
// Sets the offset and null indicator position of 'this'.
// @param offset Offset in bytes from the start of the row of the accumulator
// @param nullByte Offset in bytes from the start of the row of the null flag
// @param nullMask The specific bit in the nullByte that stores the null flag
// @param initializedByte Offset in bytes from the start of the row of the
// initialized flag
// @param initializedMask The specific bit in the initializedByte that stores
// the initialized flag
// @param rowSizeOffset The offset of a uint32_t row size from the start of
// the row. Only applies to accumulators that store variable size data out of
// line. Fixed length accumulators do not use this. 0 if the row does not have
// a size field.
void setOffsets(
int32_t offset,
int32_t nullByte,
uint8_t nullMask,
int32_t initializedByte,
int8_t initializedMask,
int32_t rowSizeOffset)
The base class implements the setOffsets method by storing the offsets in member variables.
// Byte position of null flag in group row.
int32_t nullByte_;
uint8_t nullMask_;
// Byte position of the initialized flag in group row.
int32_t initializedByte_;
uint8_t initializedMask_;
// Offset of fixed length accumulator state in group row.
int32_t offset_;
// Offset of uint32_t row byte size of row. 0 if there are no
// variable width fields or accumulators on the row. The size is
// capped at 4G and will stay at 4G and not wrap around if growing
// past this. This serves to track the batch size when extracting
// rows. A size in excess of 4G would finish the batch in any case,
// so larger values need not be represented.
int32_t rowSizeOffset_ = 0;
Typically, an aggregate function doesn’t use the offsets directly. Instead, it uses helper methods from the base class.
To access the accumulator:
template <typename T>
T* value(char* group) const {
return reinterpret_cast<T*>(group + offset_);
}
To manipulate the null flags:
bool isNull(char* group) const;
// Sets null flag for all specified groups to true.
// For any given group, this method can be called at most once.
void setAllNulls(char** groups, folly::Range<const vector_size_t*> indices);
inline bool clearNull(char* group);
Initialization¶
Once you have accumulatorFixedWidthSize(), the next method to implement is initializeNewGroupsInternal().
// Initializes null flags and accumulators for newly encountered groups.
// @param groups Pointers to the start of the new group rows.
// @param indices Indices into 'groups' of the new entries.
virtual void initializeNewGroupsInternal(
char** groups,
folly::Range<const vector_size_t*> indices) = 0;
This method is called by the HashAggregation operator every time it encounters new combinations of the grouping keys. This method should initialize the accumulators for the new groups. For example, partial “count” and “sum” aggregates would set the accumulators to zero. Many aggregate functions would set null flags to true by calling the exec::Aggregate::setAllNulls(groups, indices) helper method.
GroupBy aggregation¶
At this point you have accumulatorFixedWidthSize() and initializeNewGroupsInternal() methods implemented. Now, we can proceed to implementing the end-to-end group-by aggregation. We need the following pieces:
- Logic for adding raw input to the accumulator:
addRawInput() method.
- Logic for producing intermediate results from the accumulator:
extractAccumulators() method.
- Logic for adding intermediate results to the accumulator:
addIntermediateResults() method.
- Logic for producing final results from the accumulator:
extractValues() method.
- Logic for adding previously spilled data back to the accumulator:
addSingleGroupIntermediateResults() method.
- Optional logic for converting raw inputs into intermediate results:
supportsToIntermediate() and toIntermediate() methods.
Some methods are only used in a subset of aggregation workflows. The following table shows which methods are used in which workflows.
Method |
Partial |
Final |
Single |
Intermediate |
Streaming |
|---|---|---|---|---|---|
addRawInput |
Y |
N |
Y |
N |
Y |
extractAccumulators |
Y |
Y (used for spilling) |
Y (used for spilling) |
Y |
Y |
addIntermediateResults |
N |
Y |
N |
Y |
Y |
extractValues |
N |
Y |
Y |
N |
Y |
addSingleGroupIntermediateResults |
N |
Y |
Y |
N |
N |
toIntermediate |
Y |
N |
N |
N |
N |
We start with the addRawInput() method which receives raw input vectors and adds the data to accumulators.
// Updates the accumulator in 'groups' with the values in 'args'.
// @param groups Pointers to the start of the group rows. These are aligned
// with the 'args', e.g. data in the i-th row of the 'args' goes to the i-th group.
// The groups may repeat if different rows go into the same group.
// @param rows Rows of the 'args' to add to the accumulators. These may not be
// contiguous if the aggregation is configured to drop null grouping keys.
// This would be the case when aggregation is followed by the join on the
// grouping keys.
// @param args Data to add to the accumulators.
// @param mayPushdown True if aggregation can be pushdown down via LazyVector.
// The pushdown can happen only if this flag is true and 'args' is a single
// LazyVector.
virtual void addRawInput(
char** groups,
const SelectivityVector& rows,
const std::vector<VectorPtr>& args,
bool mayPushdown = false) = 0;
addRawInput() method would use DecodedVector’s to decode the input data. Then, loop over rows to update the accumulators. It is a good practice to define a member variable of type DecodedVector for each input vector. This allows for reusing the memory needed to decode the inputs between batches of input.
After implementing the addRawInput() method, we proceed to adding logic for extracting intermediate results.
// Extracts partial results (used for partial and intermediate aggregations).
// This method is expected to not modify contents in accumulators.
// @param groups Pointers to the start of the group rows.
// @param numGroups Number of groups to extract results from.
// @param result The result vector to store the results in.
virtual void
extractAccumulators(char** groups, int32_t numGroups, VectorPtr* result) = 0;
Next, we implement the addIntermediateResults() method that receives intermediate results and updates accumulators.
virtual void addIntermediateResults(
char** groups,
const SelectivityVector& rows,
const std::vector<VectorPtr>& args,
bool mayPushdown = false) = 0;
Next, we implement the extractValues() method that extracts final results from the accumulators.
// Extracts final results (used for final and single aggregations). This method
// is expected to not modify contents in accumulators.
// @param groups Pointers to the start of the group rows.
// @param numGroups Number of groups to extract results from.
// @param result The result vector to store the results in.
virtual void
extractValues(char** groups, int32_t numGroups, VectorPtr* result) = 0;
Finally, we implement the addSingleGroupIntermediateResults() method that is used to add previously spilled data back to the accumulator.
// Updates the single final accumulator from intermediate results for global
// aggregation.
// @param group Pointer to the start of the group row.
// @param rows Rows of the 'args' to add to the accumulators. These may not
// be contiguous if the aggregation has mask. 'rows' is guaranteed to have at
// least one active row.
// @param args Intermediate results produced by extractAccumulators().
// @param mayPushdown True if aggregation can be pushdown down via LazyVector.
// The pushdown can happen only if this flag is true and 'args' is a single
// LazyVector.
virtual void addSingleGroupIntermediateResults(
char* group,
const SelectivityVector& rows,
const std::vector<VectorPtr>& args,
bool mayPushdown) = 0;
Finally, we can implement optional methods for converting raw inputs into intermediate results. If partial aggregation encounters mostly unique keys and not able to meaningfully reduce cardinality, the operator may decide to abandon partial aggregation. In this case, the operator first emits already accumulated data (as in the case of flushing due to memory pressure), then converts each new batch of input into intermediate results and emit it right away. By default, to convert raw inputs into intermediate results, the operator creates fake groups, one per input row, initializes these groups by calling initializeNewGroups, adds each row to its own group using addRawInput, then calls extractAccumulators. This works, but is not very efficient. Individual aggregate functions can provide a more efficient implementation by implementing toIntermediate() method. If they decide to do so, they should also override supportsToIntermediate() method. For example, min and max aggregate functions implement toIntermediate() method which simply returns the input unmodified.
/// Returns true if toIntermediate() is supported.
virtual bool supportsToIntermediate() const {
return false;
}
/// Produces an accumulator initialized from a single value for each
/// row in 'rows'. The raw arguments of the aggregate are in 'args',
/// which have the same meaning as in addRawInput. The result is
/// placed in 'result'. 'result' is expected to be a writable flat vector of
/// the right type.
///
/// @param rows A set of rows to produce intermediate results for. The
/// 'result' is expected to have rows.size() rows. Invalid rows represent rows
/// that were masked out, these need to have correct intermediate results as
/// well. It is possible that all entries in 'rows' are invalid (masked out).
virtual void toIntermediate(
const SelectivityVector& rows,
std::vector<VectorPtr>& args,
VectorPtr& result) const {
VELOX_NYI("toIntermediate not supported");
}
GroupBy aggregation code path is done. We proceed to global aggregation.
Global aggregation¶
Global aggregation is similar to group-by aggregation, but there is only one group and one accumulator. After implementing group-by aggregation, the only thing needed to enable global aggregation is to implement addSingleGroupRawInput() method (addSingleGroupIntermediateResults() method is already implemented as it is used for spilling group by).
// Updates the single accumulator used for global aggregation.
// @param group Pointer to the start of the group row.
// @param allRows A contiguous range of row numbers starting from 0.
// @param args Data to add to the accumulators.
// @param mayPushdown True if aggregation can be pushdown down via LazyVector.
// The pushdown can happen only if this flag is true and 'args' is a single
// LazyVector.
virtual void addSingleGroupRawInput(
char* group,
const SelectivityVector& allRows,
const std::vector<VectorPtr>& args,
bool mayPushdown) = 0;
Spilling is not helpful for global aggregations, hence, it is not supported. The following table shows which methods are used in different global aggregation workflows.
Method |
Partial |
Final |
Single |
Intermediate |
Streaming |
|---|---|---|---|---|---|
addSingleGroupRawInput |
Y |
N |
Y |
N |
Y |
extractAccumulators |
Y |
N |
N |
Y |
Y |
addSingleGroupIntermediateResults |
N |
Y |
N |
Y |
Y |
extractValues |
N |
Y |
Y |
N |
Y |
Global aggregation is also used by the window operator. For each row, a global accumulator is cleared (clear + initializeNewGroups), then all rows in a window frame are added (addSingleGroupRawInput), then result is extracted (extractValues).
When computing running totals, i.e. when window frame is BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW, window operator re-uses the accumulator for multiple rows without resetting. For each row, window operator adds that row to the accumulator, then extracts results. The aggregate function sees a repeated sequence of addSingleGroupRawInput + extractValues calls and needs to handle these correctly.
Factory function¶
We can now write a factory function that creates an instance of the new aggregation function and register it by calling exec::registerAggregateFunction (…) and specifying function name and signatures.
HashAggregation operator uses this function to create an instance of the aggregate function. A new instance is created for each thread of execution. When partial aggregation runs on 5 threads, it uses 5 instances of each aggregate function.
Factory function takes core::AggregationNode::Step (partial/final/intermediate/single) which tells what type of input to expect, input type and result type.
exec::AggregateRegistrationResult registerApproxPercentile(const std::string& name) {
std::vector<std::shared_ptr<exec::AggregateFunctionSignature>> signatures;
...
return exec::registerAggregateFunction(
name,
std::move(signatures),
[name](
core::AggregationNode::Step step,
const std::vector<TypePtr>& argTypes,
const TypePtr& resultType) -> std::unique_ptr<exec::Aggregate> {
if (step == core::AggregationNode::Step::kIntermediate) {
return std::make_unique<ApproxPercentileAggregate<double>>(
false, false, VARBINARY());
}
auto hasWeight = argTypes.size() == 3;
TypePtr type = exec::isRawInput(step) ? argTypes[0] : resultType;
switch (type->kind()) {
case TypeKind::BIGINT:
return std::make_unique<ApproxPercentileAggregate<int64_t>>(
hasWeight, resultType);
case TypeKind::DOUBLE:
return std::make_unique<ApproxPercentileAggregate<double>>(
hasWeight, resultType);
...
}
});
}
static bool FB_ANONYMOUS_VARIABLE(g_AggregateFunction) =
registerApproxPercentile(kApproxPercentile);
If the aggregation function is implemented through the simple-function interface, use SimpleAggregateAdapter<FunctionClassName> when creating the unique pointers. Below is an example.
exec::AggregateRegistrationResult registerSimpleArrayAggAggregate(
const std::string& name) {
...
return exec::registerAggregateFunction(
name,
std::move(signatures),
[name](
core::AggregationNode::Step step,
const std::vector<TypePtr>& argTypes,
const TypePtr& resultType,
const core::QueryConfig& /*config*/)
-> std::unique_ptr<exec::Aggregate> {
VELOX_CHECK_EQ(
argTypes.size(), 1, "{} takes at most one argument", name);
return std::make_unique<SimpleAggregateAdapter<SimpleArrayAggAggregate>>(
step, argTypes, resultType);
});
}
Use FunctionSignatureBuilder to create FunctionSignature instances which describe supported signatures. Each signature includes zero or more input types, an intermediate result type and final result type.
FunctionSignatureBuilder and FunctionSignature support Java-like generics, variable number of arguments and lambdas. See more in Function signature section of the How to add a scalar function? guide.
Here is an example of signatures for the approx_percentile() function. This
functions takes value argument of a numeric type, an optional weight argument
of type INTEGER, and a percentage argument of type DOUBLE. The intermediate
type does not depend on the input types and is always VARBINARY. The final
result type is the same as input value type.
for (const auto& inputType :
{"tinyint", "smallint", "integer", "bigint", "real", "double"}) {
// (x, double percentage) -> varbinary -> x
signatures.push_back(exec::AggregateFunctionSignatureBuilder()
.returnType(inputType)
.intermediateType("varbinary")
.argumentType(inputType)
.argumentType("double")
.build());
// (x, integer weight, double percentage) -> varbinary -> x
signatures.push_back(exec::AggregateFunctionSignatureBuilder()
.returnType(inputType)
.intermediateType("varbinary")
.argumentType(inputType)
.argumentType("bigint")
.argumentType("double")
.build());
}
Testing¶
It is time to put all the pieces together and test how well the new function works.
Use AggregationTestBase from velox/aggregates/tests/AggregationTestBase.h as a base class for the test.
If the new aggregate function is supported by DuckDB, you can use DuckDB to check results. In this case you specify input data, grouping keys, a list of aggregates and a SQL query to run on DuckDB to calculate the expected results and call helper function testAggregates defined in AggregationTestBase class. Grouping keys can be empty for global aggregations.
// Global aggregation.
testAggregations(vectors, {}, {"sum(c1)"}, "SELECT sum(c1) FROM tmp");
// Group by aggregation.
testAggregations(
vectors, {"c0"}, {"sum(c1)"}, "SELECT c0, sum(c1) FROM tmp GROUP BY 1");
If the new function is not supported by DuckDB, you need to specify the expected results manually.
// Global aggregation.
testAggregations(vectors, {}, {"map_union(c1)"}, expectedResult);
// Group by aggregation.
testAggregations(vectors, {"c0"}, {"map_union(c1)"}, expectedResult);
Under the covers, testAggregations method generates multiple different but logically equivalent plans, executes these plans, verifies successful completion and compares the results with DuckDB or specified expected results.
The following query plans are being tested.
Partial aggregation followed by final aggregation. Query runs single-threaded.
Single aggregation. Query runs single-threaded.
Partial aggregation followed by intermediate aggregation followed by final aggregation. Query runs single-threaded.
Partial aggregation followed by local exchange on the grouping keys followed by final aggregation. Query runs using 4 threads.
Local exchange using round-robin repartitioning followed by partial aggregation followed by local exchange on the grouping keys followed by final aggregation with forced spilling. Query runs using 4 threads.
Query run with forced spilling is enabled only for group-by aggregations and
only if aggregate functions are not order-sensitive. Spill testing requires multiple batches of input.
To split input data into multiple batches we add local exchange with
round-robin repartitioning before the partial aggregation. This changes the order
in which aggregation inputs are processed, hence, query results with spilling
are expected to be the same as without spilling only if aggregate functions used
in the query are not sensitive to the order of inputs. Many functions produce
the same results regardless of the order of inputs, but some functions may return
different results if inputs are provided in a different order. For
example, arbitrary(), array_agg(), map_agg() and
map_union() functions are sensitive to the order of inputs,
and min_by() and max_by() functions are sensitive to the order of
inputs in the presence of ties.
Function names¶
Same as scalar functions, aggregate function names are case insensitive. The names are converted to lower case automatically when the functions are registered and when they are resolved for a given expression.
Documentation¶
Finally, document the new function by adding an entry to velox/docs/functions/presto/aggregate.rst
You can see the documentation for all functions at Aggregate Functions and read about how documentation is generated at https://github.com/facebookincubator/velox/tree/main/velox/docs#velox-documentation
Accumulator¶
In Velox, efficient use of memory is a priority. This includes both optimizing the total amount of memory used as well as the number of memory allocations. Note that runtime statistics reported by Velox include both peak memory usage (in bytes) and number of memory allocations for each operator.
Aggregate functions use memory to store intermediate results in the accumulators. They allocate memory from an arena (HashStringAllocator class).
StlAllocator is an STL-compatible allocator backed by HashStringAllocator that can be used with STL containers. For example, one can define an std::vector that allocates memory from the arena like so:
std::vector<int64_t, StlAllocator<int64_t>>
This is used, for example, in 3-arg versions of min_by() and max_by() with
fixed-width type inputs (e.g. integers).
There is also an AlignedStlAllocator that provides aligned allocations from the arena and can be used with F14 containers which require 16-byte alignment. One can define an F14FastMap that allocates memory from the arena like so:
folly::F14FastMap<
int64_t,
double,
std::hash<int64_t>,
std::equal_to<int64_t>,
AlignedStlAllocator<std::pair<const int64_t, double>, 16>>
You can find an example usage in histogram() aggregation function.
An array_agg() function on primitive types could be implemented using
std::vector<T>, but it would not be efficient. Why is that? If one doesn’t
use ‘reserve’ method to provide a hint to std::vector about how many entries will be
added, the default behavior is to allocate memory in powers of 2, e.g. first
allocate 1 entry, then 2, then 4, 8, 16, etc. Every time new allocation is
made the data is copied into the new memory buffer and the old buffer is
released. One can see this by instrumenting StlAllocator::allocate and
deallocate methods to add logging and run a simple loop to add elements to a
vector:
std::vector<double, StlAllocator<double>> data(
0, StlAllocator<double>(allocator_.get()));
for (auto i = 0; i < 100; ++i) {
data.push_back(i);
}
E20230714 14:57:33.717708 975289 HashStringAllocator.h:497] allocate 1
E20230714 14:57:33.734280 975289 HashStringAllocator.h:497] allocate 2
E20230714 14:57:33.734321 975289 HashStringAllocator.h:506] free 1
E20230714 14:57:33.734352 975289 HashStringAllocator.h:497] allocate 4
E20230714 14:57:33.734381 975289 HashStringAllocator.h:506] free 2
E20230714 14:57:33.734416 975289 HashStringAllocator.h:497] allocate 8
E20230714 14:57:33.734445 975289 HashStringAllocator.h:506] free 4
E20230714 14:57:33.734481 975289 HashStringAllocator.h:497] allocate 16
E20230714 14:57:33.734513 975289 HashStringAllocator.h:506] free 8
E20230714 14:57:33.734544 975289 HashStringAllocator.h:497] allocate 32
E20230714 14:57:33.734575 975289 HashStringAllocator.h:506] free 16
E20230714 14:57:33.734606 975289 HashStringAllocator.h:497] allocate 64
E20230714 14:57:33.734637 975289 HashStringAllocator.h:506] free 32
E20230714 14:57:33.734668 975289 HashStringAllocator.h:497] allocate 128
E20230714 14:57:33.734699 975289 HashStringAllocator.h:506] free 64
E20230714 14:57:33.734731 975289 HashStringAllocator.h:506] free 128
Reallocating memory and copying data is not cheap. To avoid this overhead we introduced ValueList primitive and used it to implement array_agg.
ValueList is an append-only data structure that allows appending values from any Velox Vector and reading values back into a Velox Vector. ValueList doesn’t require a contiguous chunk of memory and therefore doesn’t need to re-allocate and copy when it runs out of space. It just allocates another chunk and starts filling that up.
ValueList is designed to work with data that comes from Velox Vectors, hence, its API is different from std::vector. You append values from a DecodedVector and read values back into a flat vector. Here is an example of usage:
DecodedVector decoded(*data);
// Store data.
ValueList values;
for (auto i = 0; i < 100; ++i) {
values.appendValue(decoded, i, allocator());
}
// Read data back.
auto copy = BaseVector::create(DOUBLE(), 100, pool());
aggregate::ValueListReader reader(values);
for (auto i = 0; i < 100; ++i) {
reader.next(*copy, i);
}
ValueList supports all types, so you can use it to append fixed-width values as well as strings, arrays, maps and structs.
When storing complex types, ValueList serializes the values using ContainerRowSerde.
ValueList preserves the null flags as well, so you can store a list of nullable values in it.
The array_agg is implemented using ValueList for the accumulator.
ValueList needs a pointer to the arena for appending data. It doesn’t take an arena in the constructor and doesn’t store it, because that would require 8 bytes of memory per group in the aggregation operator. Instead, ValueList::appendValue method takes a pointer to the arena as an argument. Consequently, ValueList’s destructor cannot release the memory back to the arena and requires the user to explicitly call the free (HashStringAllocator*) method.
min() and max() functions store a single value in the accumulator
(the current min or max value). They use SingleValueAccumulator to store
strings, arrays, maps and structs. When processing a new value, we compare
it with the stored value and replace the stored value if necessary.
Similar to ValueList, SingleValueAccumulator serializes the values using ContainerRowSerde. SingleValueAccumulator provides a compare method to compare stored value with a row of a DecodedVector.
This accumulator is also used in the implementation of the arbitrary()
aggregate function which stores the first value in the accumulator.
set_agg() function accumulates a set of unique values into an F14FastSet
configured to allocate memory from the arena via AlignedStlAllocator.
Fixed-width values are stored directly in F14FastSet. Memory allocation pattern
for F14 data structures is similar to std::vector. F14 allocates memory in
powers on 2, copies data and frees previously allocated memory. Hence, we do
not store strings directly in the F14 set. Instead, Velox writes strings into
the arena and stores a StringView pointing to the arena in the set.
In general, when writing to the arena, one is not guaranteed a contiguous write. However, for StringViews to work we must ensure that strings written into the arena are contiguous. Strings helper class provides this functionality. Its append method takes a StringView and a pointer to the arena, copies the string into the arena and returns a StringView pointing to the copy.
/// Copies the string into contiguous memory allocated via
/// HashStringAllocator. Returns StringView over the copy.
StringView append(StringView value, HashStringAllocator& allocator);
Strings class provides a free method to release memory back to the arena.
/// Frees memory used by the strings. StringViews returned from 'append'
/// become invalid after this call.
void free(HashStringAllocator& allocator);
When aggregating complex types (arrays, maps or structs), we use AddressableNonNullValueList which writes values to the arena and returns a “pointer” to the written value which we store in the F14 set. AddressableNonNullValueList provides methods to compute a hash of a value and compare two values. AddressableNonNullValueList uses ContainerRowSerde for serializing data and comparing serialized values.
/// A set of pointers to values stored in AddressableNonNullValueList.
SetAccumulator<
HashStringAllocator::Position,
AddressableNonNullValueList::Hash,
AddressableNonNullValueList::EqualTo>
base;
AddressableNonNullValueList allows to append a value and erase the last value. This functionality is sufficient for set_agg and set_union. When processing a new value, we append it to the list, get a “pointer”, insert that “pointer” into F14 set and if the “pointer” points to a duplicate value we remove it from the list.
Like all other arena-based accumulators, AddressableNonNullValueList provides a free method to return memory back to the arena.
Note: AddressableNonNullValueList is different from ValueList in that it provides access to individual values (hence, the “Addressable” prefix in the name) while ValueList does not. With ValueList one can append values, then copy all the values into a Vector. Adhoc access to individual elements is not available in ValueList.
SetAccumulator<T> template implements a simple interface to accumulate unique values. It is implemented using F14FastSet, Strings and AddressableNonNullValueList. T can be a fixed-width type like int32_t or int64_t, StringView or ComplexType.
addValue and addValues method allow to add one or multiple values from a vector.
/// Adds value if new. No-op if the value was added before.
void addValue(
const DecodedVector& decoded,
vector_size_t index,
HashStringAllocator* allocator)/// Adds new values from an array.
void addValues(
const ArrayVector& arrayVector,
vector_size_t index,
const DecodedVector& values,
HashStringAllocator* allocator)
size() method returns the number of unique values.
/// Returns number of unique values including null.
size_t size() const
extractValues method allows to extract unique values into a vector.
/// Copies the unique values and null into the specified vector starting at
/// the specified offset.
vector_size_t extractValues(FlatVector<T>& values, vector_size_t offset)
/// For complex types.
vector_size_t extractValues(BaseVector& values, vector_size_t offset)
Both set_agg() and set_union() functions are implemented using
SetAccumulator.
map_agg() function accumulates keys and values into a map. It discards
duplicate keys and keeps only one value for each unique key. Map_agg uses
MapAccumulator<T> template to accumulate the values. Similar to SetAccumulator,
MapAccumulator is built using F14FastMap, AlignedStlAllocator, Strings and
AddressableNonNullValueList.
insert() method adds a pair of (key, value) to the map discarding the value if matching key already exists.
/// Adds key-value pair if entry with that key doesn't exist yet.
void insert(
const DecodedVector& decodedKeys,
const DecodedVector& decodedValues,
vector_size_t index,
HashStringAllocator& allocator)
size() method returns the number of unique values.
extract() method copies the keys and the values into vectors, which can be combined to form a MapVector.
void extract(
const VectorPtr& mapKeys,
const VectorPtr& mapValues,
vector_size_t offset)
Both map_agg() and map_union() functions are implemented using
MapAccumulator.
When implementing new aggregate functions, consider using ValueList, SingleValueAccumulator, Strings, AddressableNonNullValueList and F14 containers to put together an accumulator that uses memory efficiently.
Aggregation operator needs to know how much memory is used for each group. For example, this information is used to decide how many and which rows to spill when memory is tight.
Aggregation functions should use RowSizeTracker to help track memory usage per group. Aggregate base class provides helper method trackRowSize(group), which can be used like so:
rows.applyToSelected([&](vector_size_t row) {
auto group = groups[row];
auto tracker = trackRowSize(group);
accumulator->append(...);
});
The ‘trackRowSize’ method returns an instance of RowSizeTracker initialized with a reference to the arena and a counter to increment on destruction. When object returned by trackRowSize goes out of scope, the counter is updated to add memory allocated since object’s creation.
End-to-End Testing¶
To confirm that aggregate function works end to end as part of query, update testAggregations() test in TestHiveAggregationQueries.java in presto_cpp repo to add a query that uses the new function.
assertQuery("SELECT orderkey, array_agg(linenumber) FROM lineitem GROUP BY 1");
Overwrite Intermediate Type in Presto¶
Sometimes we need to change the intermediate type of aggregation function in
Presto, due to the differences in implementation or in the type information
worker node receives. This is done in Presto class
com.facebook.presto.metadata.BuiltInTypeAndFunctionNamespaceManager. When
FeaturesConfig.isUseAlternativeFunctionSignatures() is enabled, we can
register a different set of function signatures used specifically by Velox. An
example of how to create such alternative function signatures from scratch can
be found in
com.facebook.presto.operator.aggregation.AlternativeApproxPercentile. An
example pull request can be found at
https://github.com/prestodb/presto/pull/18386.