Joins¶
Velox supports inner, left, right, full outer, left semi filter, left semi project, right semi filter, right semi project, anti, and counting hash joins using either partitioned or broadcast distribution strategies. Semi project and anti joins support additional null-aware flag to distinguish between IN (null aware) and EXISTS (regular) semantics. Anti, left semi filter, and counting joins support a null-as-value flag that enables IS NOT DISTINCT FROM semantics for join keys (NULL equals NULL), used to implement SQL set operations (EXCEPT, INTERSECT, EXCEPT ALL, INTERSECT ALL). Velox also supports cross joins.
Velox also supports inner and left merge join for the case where join inputs are sorted on the join keys. Right, full, left semi, right semi, and anti merge joins are not supported yet.
Hash Join Implementation¶
Use HashJoinNode plan node to insert a join into a query plan. Specify the join type, an equi-clause, e.g. pairs of columns on the left and right side whose values need to match, and an optional filter to apply to join results.

The join type can be one of kInner, kLeft, kRight, kFull, kLeftSemiFilter, kCountingLeftSemiFilter, kLeftSemiProject, kRightSemiFilter, kRightSemiProject, kAnti, or kCountingAnti.
kLeftSemiProject, kRightSemiProject and kAnti joins support an additional nullAware flag to distinguish between IN (null aware) and EXISTS (regular) semantics. See Anti joins for detailed semantics.
kAnti, kLeftSemiFilter, kCountingAnti, and kCountingLeftSemiFilter joins support an additional nullAsValue flag that makes join keys use IS NOT DISTINCT FROM semantics where NULL equals NULL. This is used to implement SQL set operations (EXCEPT, INTERSECT, EXCEPT ALL, INTERSECT ALL) which require NULLs to match. The nullAsValue and nullAware flags are mutually exclusive.
Filter is optional. If specified it can be any expression over the results of the join. This expression will be evaluated using the same expression evaluation engine as used by the FilterProject operator and HiveConnector.
Inner join with a filter is equivalent to a join operator followed by FilterProject operator, but left join with a filter is different. Left join returns all rows from the left side along with all the matches on the build side that pass the filter. The results also include rows from the left side for which there is no match on the build side or neither match passed the filter.
To illustrate the difference between the left join with a filter and a left join followed by a filter consider the following data.
Left side:
id |
value |
|---|---|
1 |
10 |
2 |
20 |
3 |
30 |
4 |
40 |
Right side:
id |
name |
|---|---|
2 |
‘a’ |
2 |
‘b’ |
3 |
‘c’ |
3 |
‘d’ |
3 |
‘e’ |
4 |
‘f’ |
The result of the left join on left.id = right.id is:
l.id |
l.value |
r.name |
|---|---|---|
1 |
10 |
null |
2 |
20 |
‘a’ |
2 |
20 |
‘b’ |
3 |
30 |
‘c’ |
3 |
30 |
‘d’ |
3 |
30 |
‘e’ |
4 |
40 |
‘f’ |
The result of the left join on left.id = right.id with a filter right.name IN (‘a’, ‘f’) is:
l.id |
l.value |
r.name |
|---|---|---|
1 |
10 |
null |
2 |
20 |
‘a’ |
3 |
30 |
null |
4 |
40 |
‘f’ |
Compare this with the result of left join on left.id = right.id followed by filter right.name IN (‘a’, ‘f’):
l.id |
l.value |
r.name |
|---|---|---|
2 |
20 |
‘a’ |
4 |
40 |
‘f’ |
To execute a plan with a join, Velox creates two separate pipelines. One pipeline processes the build side data and creates a hash table. The other pipeline processes the data on the probe side, joins it with the build side data by probing the hash table and continues execution as specified by downstream plan nodes. HashJoinNode is translated into two separate operators: HashProbe and HashBuild. HashProbe operator becomes part of the probe-side pipeline. HashBuild operator is installed as the last operator of the build-side pipeline. The output of the HashBuild operator is a hash table which HashProbe operator gets access to via a special mechanism: JoinBridge.
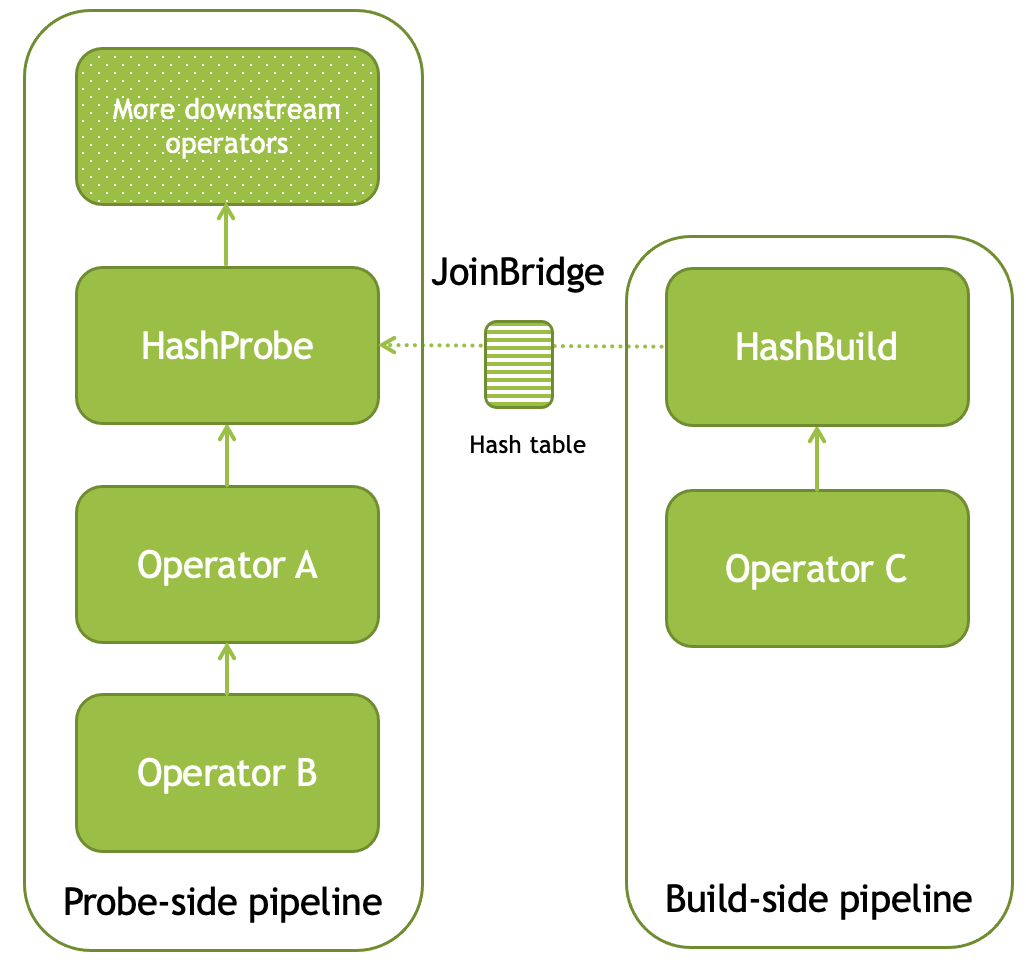
Both HashBuild and HashAggregation operators use the same data structure for the hash table: HashTable. The payload, the non-join key columns referred to as dependent columns, are stored row-wise in the RowContainer.
Using the hash table in join and aggregation allows for a future optimization where the hash table can be reused if the aggregation is followed by the join and aggregation and join keys are the same. We expect to implement this optimization in the near future, but it is currently not implemented.
While processing input and building a hash table HashBuild operator analyzes the values of the join keys to determine whether these keys can be normalized (e.g. multiple keys can be merged into a single 64-bit integer key) or mapped to a small integer domain to allow for array-based lookup. This mechanism is implemented in the velox::exec::VectorHasher and is shared between aggregations and joins.
Build and probe side pipelines can run multi-threaded and their parallelism can be specified independently. HashBuild operator has extra logic to support parallel building of the hash table where the operator that finishes building its table last is responsible for merging it with all the other hash tables before making the hash table available over the JoinBridge.
Dynamic Filter Pushdown¶
In some queries the join runs in the same stage as the probe-side table scan. This happens if the join build side is broadcasted (when it is small enough) to all join nodes or if the query is using bucket-by-bucket execution mode. In these scenarios, it is often the case that only a small fraction of the join keys on the probe side match the build side and it is beneficial to filter out probe rows during table scan. This optimization is referred to as dynamic filtering or dynamic filter pushdown.
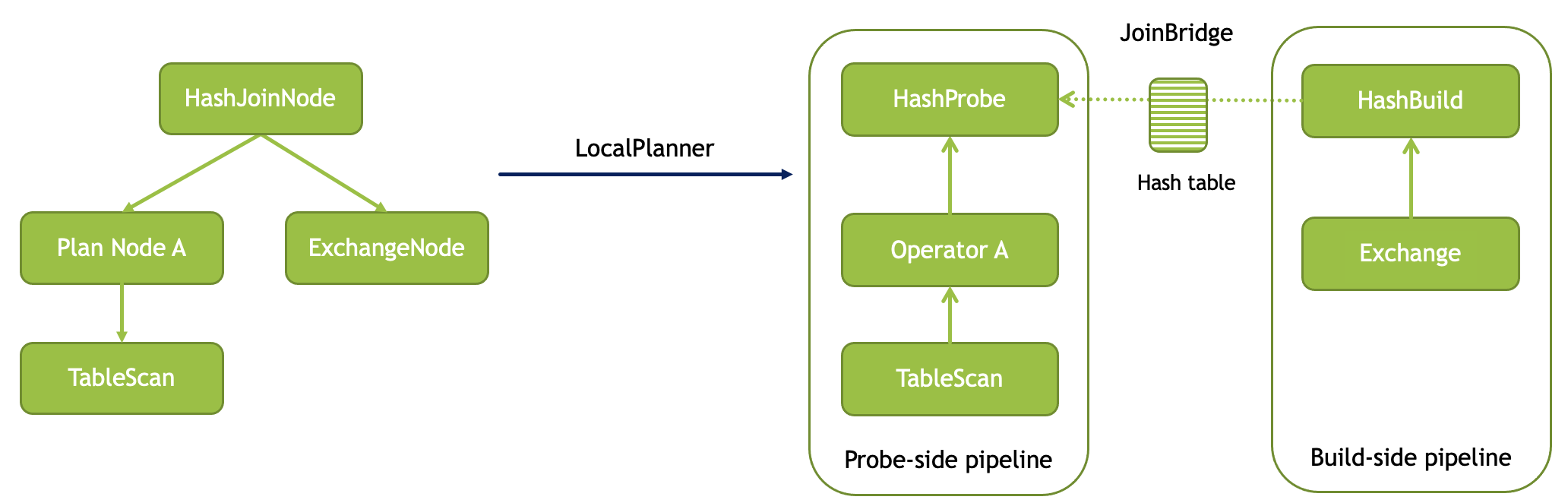
Velox implements this optimization by leveraging VectorHashers that contain full knowledge about the join key values on the build side. For each join key with not too many distinct values, an in-list filter is constructed using the set of distinct values stored in the corresponding VectorHasher. These filters are then pushed down into the TableScan operator and make their way into the HiveConnector which uses them to (1) prune files and row groups based on statistics and (2) filter out rows when reading the data.
It is worth noting that the biggest wins come from using the dynamic filters to prune whole file and row groups during table scan.
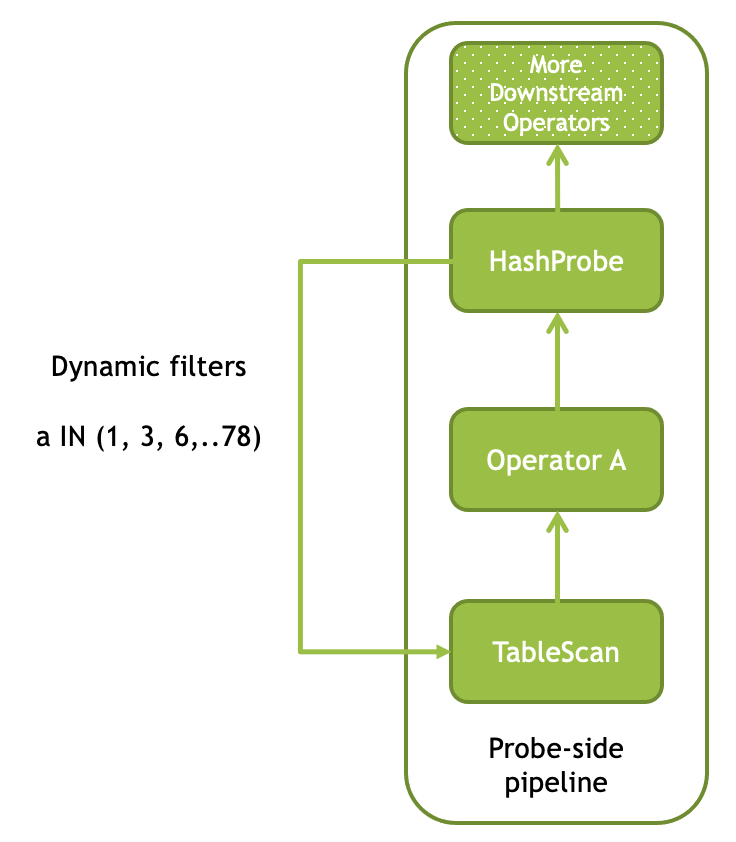
Dynamic filter pushdown is possible only if the join key column comes from a collocated TableScan operator unmodified. HashProbe asks the Driver which columns support filter pushdown (e.g. which columns come unmodified from an operator which accepts dynamic filters) and generates filters only for such columns.
In cases when the join has a single join key and no dependent columns and all join key values on the build side are unique it is possible to replace the join completely with the pushed down filter. Velox detects such opportunities and turns the join into a no-op after pushing the filter down.
Dynamic filter pushdown optimization is enabled for inner, left semi, right semi and right joins.
Broadcast Join¶
Broadcast join refers to a specific distributed execution strategy where the build side is small enough that it can be copied (broadcasted) to all the join nodes and that allows to avoid re-shuffling the probe and build sides to arrange for all rows with the same keys to appear on the same machine. Whether the join is executed using broadcast or partitioned strategy has no effect on the join execution itself. The only difference is that broadcast execution allows for dynamic filter pushdown while partitioned execution does not.
HashJoinNode supports a useHashTableCache flag (used only by Presto-on-Spark)
that enables caching of the hash table built for broadcast joins. When enabled,
the first task to build the hash table stores it in a global cache, and subsequent
tasks from same query reuse the cached table instead of rebuilding it. See
Broadcast Build Caching for details.
PartitionedOutput operator and OutputBufferManager support broadcasting the results of the plan evaluation. This functionality is enabled by setting boolean flag “broadcast” in the PartitionedOutputNode to true.
Anti Joins¶
Null aware anti join is used for queries with NOT IN <subquery> clause, while regular anti join is used for queries with NOT EXISTS <subquery> clause.
-- null-aware anti join
SELECT * FROM t WHERE t.key NOT IN (SELECT key FROM u)
-- regular anti join
SELECT * FROM t WHERE NOT EXISTS (SELECT * FROM u WHERE u.key = t.key)
Broadly-speaking anti join returns probe-side rows which have no match on the build side. However, the exact semantics are a bit tricky. These are described in detail in Anti joins.
At a high level, null-aware anti join without extra filter behaves as follows:
return empty dataset if the build side contains an entry with a null in any of the join keys;
return all rows from the probe side, including rows with nulls in the join key, when the build side is empty;
returns probe-side rows with non-null join keys and no match in the build side when build side is not empty.
When a query runs on multiple machines, the cases (1) and (2) cannot be easily identified locally (unless the join runs in broadcast mode) as they require knowledge about the whole build side. It is necessary to know whether the combined build side across all nodes is empty and if not if it contains a null key. To provide this information locally, PartitionedOutput operator supports a mode where it replicates all rows with nulls in the partitioning keys to all destinations and in case there are no rows with null keys replicates one arbitrary chosen row to all destinations. This mode is enabled by setting the “replicateNullsAndAny” flag to true in the PartitionedOutputNode plan node.
Replicate-nulls-and-any function of the PartitionedOutput operator ensures that all nodes receive rows with nulls in join keys and therefore can implement the semantics described in (1). It also ensures that local build sides are empty only if the whole build side is empty, allowing to implement semantic (2). Sending one row with a non-null key to multiple “wrong” destinations is safe because that row cannot possibly match anything on these destinations.
Semi Joins¶
Semi filter joins are used for queries with IN <subquery> and EXISTS <subquery> clauses. Left semi filter join should be used when cardinality of the outer query is greater than cardinality of the subquery. Right semi join can be used when cardinality of the subquery is greater.
SELECT * FROM t WHERE t.key IN (SELECT key FROM u)
SELECT * FROM t WHERE EXISTS (SELECT * FROM u WHERE u.key = t.key)
Left semi filter join returns probe-side rows which have at least one match on the build side. Right semi filter join returns build-side rows which have at least one match on the probe side.
Semi project joins are used for queries where IN <subquery> or EXISTS <subquery> expressions are combined with other expressions.
SELECT * FROM t WHERE t.key IN (SELECT key FROM u) OR t.col > 10
SELECT * FROM t WHERE t.key NOT IN (...) OR t.key2 NOT IN (...)
Left semi project join returns all probe-side rows with an extra boolean column (match) indicating whether there is a match on the build side. Right semi project join returns all build-side rows with the ‘match’ column indicating whether there is a match on the probe side.
Semi project joins support null-aware flag to distinguish between IN and EXISTS semantics. Null-aware semi project join may return NULL value if it is not possible to definitively say whether there is a match or not. For example, left semi project join without extra filter returns NULL for a probe-side row with a NULL in the join key as long as build-side is not empty.
The results of the anti join are equivalent to the results of a semi project join followed by a ‘NOT match’ filter.
Empty Build Side¶
For inner, left semi, and right semi joins, when the build side is empty, Velox implements an optimization to finish the join early and return an empty set of results without waiting to receive all the probe side input. In this case all upstream operators are canceled to avoid unnecessary computation.
Small Build Side Inputs¶
Nested loop join materializes the entire build side before producing output. When the build side is small enough to fit into a single row or a single vector, Velox uses specialized paths to avoid processing one probe row at a time.
If the build side has a single row, build-side projections are wrapped as
constants and evaluated against the whole probe batch at once. If the build
side has a single vector, Velox wraps probe-side and build-side rows in
dictionaries and evaluates the join condition over a batched cross product that
covers as many probe rows as fit within outputBatchSize_.
These paths reduce repeated cross-product materialization and join-condition setup for small build inputs while preserving the usual nested loop join semantics, including probe-side output order for inner and left joins. If the build side spans multiple vectors, Velox falls back to processing one probe row against one build vector at a time.
Skipping Duplicate Keys¶
When building a hash table for left semi or anti join, HashBuild operator skips entries with duplicate keys as these are not needed. This is achieved by configuring exec::HashTable to set the “allowDuplicates” flag to false. This optimization reduces memory usage of the hash table in case the build side contains duplicate join keys.
Counting Joins¶
Counting joins (kCountingAnti and kCountingLeftSemiFilter) are multiset variants of kAnti and kLeftSemiFilter used to implement EXCEPT ALL and INTERSECT ALL respectively.
EXCEPT and INTERSECT treat both inputs as sets: they remove duplicates and return distinct rows. EXCEPT ALL and INTERSECT ALL preserve duplicates and operate on multisets: each row is considered independently.
-- EXCEPT removes duplicates:
-- {A, A, A, B, B} EXCEPT {A, C} = {A, B} (just "is A present?")
-- EXCEPT ALL counts duplicates:
-- {A, A, A, B, B} EXCEPT ALL {A, C} = {A, A, B, B} (remove one A)
-- INTERSECT removes duplicates:
-- {A, A, A, B, B} INTERSECT {A, A, C} = {A} (just "is A present?")
-- INTERSECT ALL counts duplicates:
-- {A, A, A, B, B} INTERSECT ALL {A, A, C} = {A, A} (keep min count)
EXCEPT ALL and INTERSECT ALL cannot be implemented using regular semi and anti joins because those only check for the existence of a match, not the number of matches. Counting joins solve this by tracking per-key counts.
The build side deduplicates keys and stores a per-key count. Unlike semi and anti joins which skip duplicate keys entirely (see Skipping Duplicate Keys above), counting joins keep exactly one entry per key with a count of how many times that key appeared.
On probe, each match decrements the count. kCountingAnti emits a probe row when the count reaches zero or no match is found (EXCEPT ALL semantics). kCountingLeftSemiFilter emits a probe row while the count is greater than zero (INTERSECT ALL semantics). Counting joins do not support extra filter or null-aware mode. Spilling is not yet supported.
Because the probe side modifies per-key counts in the hash table (decrementing on each match), it must run either single-threaded or with the probe input partitioned on join keys across threads. Without partitioning, multiple probe threads could decrement the same key’s count concurrently, producing incorrect results. The build side can run multi-threaded: each build driver constructs its own hash table, and these are merged by summing per-key counts for duplicate keys.
Execution Statistics¶
HashBuild operator reports the hash table mode, the range and number of distinct values for each join key if these are not too large and allow for array-based join or use of normalized keys.
hashtable.hashMode - the hash mode of the table: 0 for kHash, 1 for kArray, 2 for kNormalizedKey
rangeKey<N> - the range of values for the join key #N
distinctKey<N> - the number of distinct values for the join key #N
HashProbe operator reports whether it replaced itself with the pushed down filter entirely and became a no-op.
replacedWithDynamicFilterRows - the number of rows which were passed through without any processing after filter was pushed down
HashProbe also reports the number of dynamic filters it generated for push down.
dynamicFiltersProduced - number of dynamic filters generated (at most one per join key)
maxSpillLevel - the max spill level that has been triggered with zero for the initial spill.
TableScan operator reports the number of dynamic filters it received and passed to HiveConnector.
dynamicFiltersAccepted - number of dynamic filters received
Memory Layout¶
The hash table stores row values in RowContainer. This is a row-wise storage and each row consists of the following components:
- Null flags (1 bit per item) for
Keys (only if nullable)
Dependants
Has-probed flag (1 bit, right and full outer joins only)
Free flag (1 bit)
Keys
Dependants
Variable size (32 bit)
Next offset (64 bit pointer, joins that allow duplicate keys)
Count (32 bit, counting joins only, mutually exclusive with Next offset)
Merge Join Implementation¶
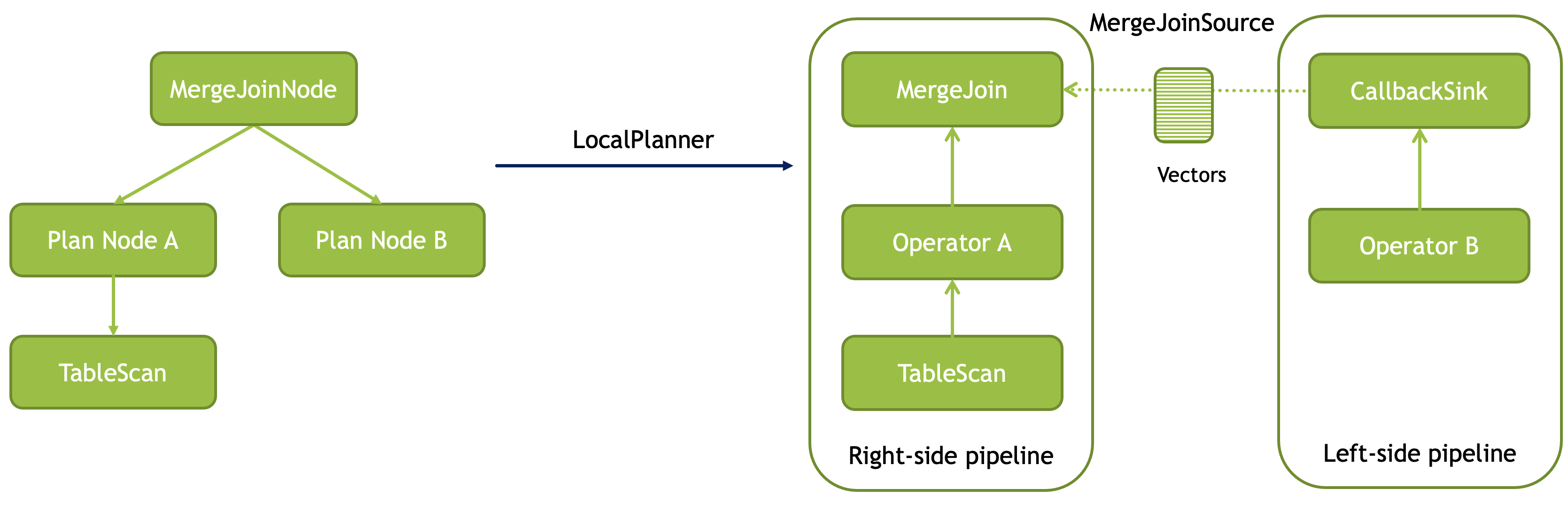
Use MergeJoinNode plan node to insert a merge join into a query plan. Make sure both left and right sides of the join produce results sorted on the join keys. Specify the join type, an equi-clause, e.g. pairs of columns on the left and right side whose values need to match, and an optional filter to apply to join results.
To execute a plan with a merge join, Velox creates two separate pipelines. One pipeline processes the right side data and puts it into MergeJoinSource. The other pipeline processes the data on the left side, joins it with the right side data and continues execution as specified by downstream plan nodes. MergeJoinNode is translated into MergeJoin operator and a CallbackSink backed by MergeJoinSource. MergeJoin operator becomes part of the left-side pipeline. CallbackSink is installed at the end of the right-side pipeline.
Usage Examples¶
Check out velox/exec/tests/HashJoinTest.cpp, CountingJoinTest.cpp, and MergeJoinTest.cpp for examples of how to build and execute a plan with a hash, counting, or merge join.