
oomd at Facebook
Sandcastle is an internal system that builds, tests, and lands code, and is one of the largest services running at Facebook.
The Sandcastle team's servers were running out of memory and their jobs were getting repeatedly OOM-killed. About 5% of Sandcastle hosts rebooted unexpectedly every day. Scaling Sandcastle by simply adding new servers was no longer a possibility due to the crunch on hardware resources.
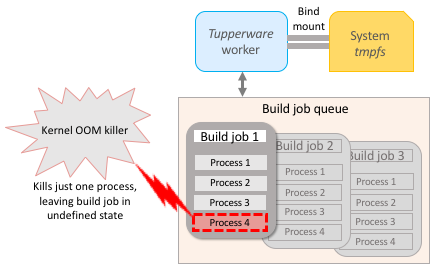
The problem—unreleased memory and arbitrary kernel OOM kills
Sandcastle machines use Tupperware, Facebook's in-house containerization solution, to run worker tasks that repeatedly fetch build jobs from a queue and run them. Sandcastle was using memory from tmpfs (an in-memory temporary filesystem) for the build jobs. When the build processes were killed they didn’t release their memory because the system’s tmpfs was bind mounted to each worker.
The solution—controlled cgroup OOM kills with oomd
The team wanted to create a cgroup architecture with the following objectives:
- Make OOM kills immediately free the
tmpfsspace the build job was using. - Make OOM kills kill an entire build job, instead of just one process within it.
Experiments and testing led the team to the following solution:
- The worker contains each build job it runs inside its own sub-cgroup. All the build job processes are contained in their own cgroup in
workload.slice. - oomd is configured to watch per-job cgroups.
- Each build job gets its own mount namespace and
tmpfsmount, instead of living off the worker’s mount namespace and bind mounting the system’stmpfs.
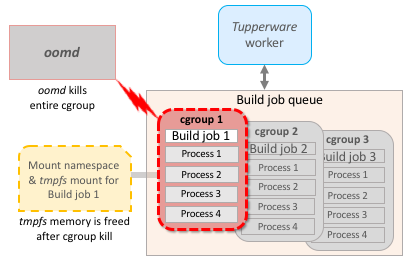
With each build job contained in its own cgroup with oomd enabled, oomd kills the entire cgroup and all its processes at once.
Because the mount namespace is only pinned by the processes in that cgroup, the mount namespace gets released, which in turn frees the tmpfs instance the build job was using.
Tupperware no longer needs to clean up the task and restart it, since only the build job is killed instead of the worker itself. The Sandcastle worker notices the build job terminated abnormally and moves on to fetching the next job as quickly as it can.
oomd in action
The chart below shows a real-world Sandcastle memory usage spike.
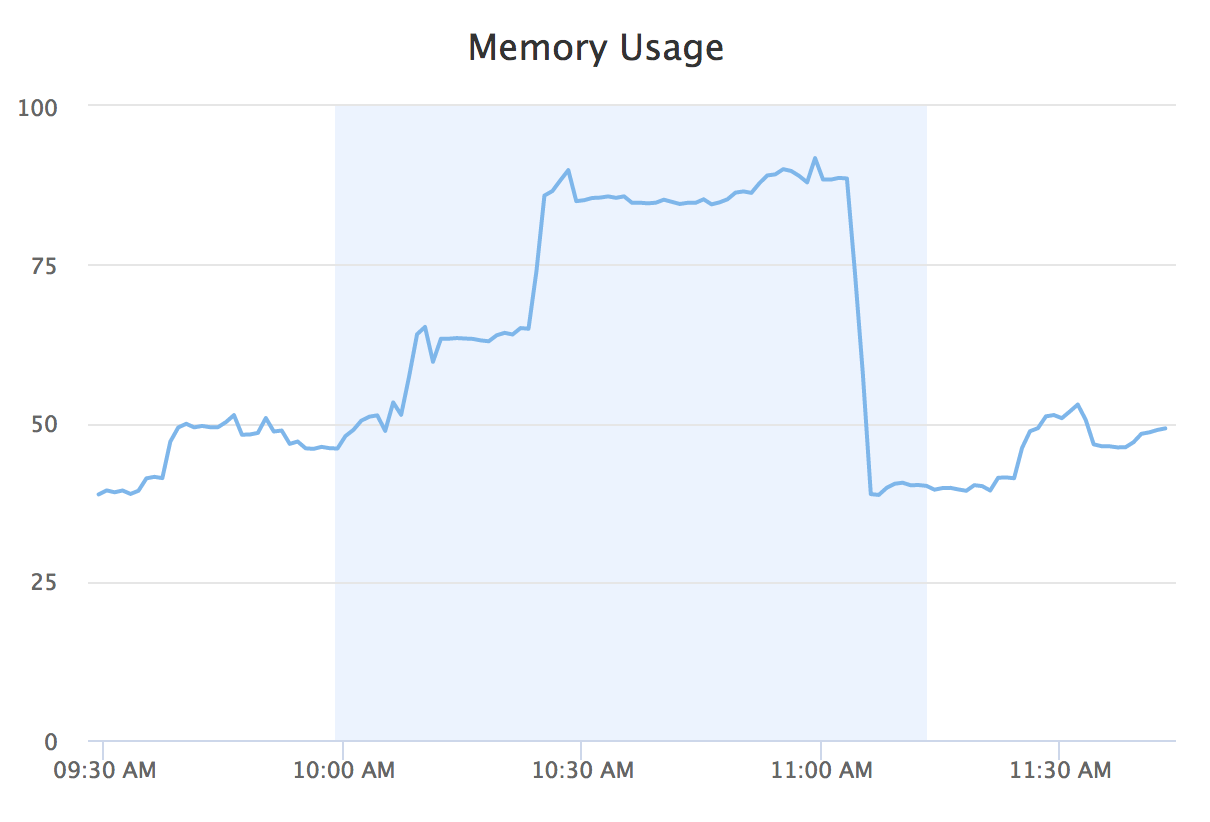
The corresponding oomd output log (located in /var/log/messages) shows the Sandcastle build job getting killed as a result of the spike in memory pressure:

Results
This solution resulted in a big impact win for the Sandcastle team: since implementing oomd, the unexpected server reboot rate dropped from 5% to less than 0.5%. Post-OOM downtimes for Sandcastle machines went from tens of minutes to just seconds, driving a 10% capacity gain.
The increased reliability also significantly increased utilization, with a 35% increase in build jobs per host.