Spilling¶
Background¶
Spilling in Velox allows a query to succeed using a limited amount of memory when some operators are accumulating large state. For example, a hash aggregation operator stores the intermediate aggregation state in a hash table, and it starts to produce the results after processing all the input. In high cardinality workloads (large number of groups) the size of the hash table exceeds the query’s memory limit.
To allow such queries to succeed, spilling kicks in and writes part of the operator’s state to disk. After operator received all input, it reads back the spilled state from disk and merges it with un-spilled state in memory to produce the result. The spilling process consists of two phases: spilling and restoring. The spilling phase is executed while the operator processes input. It decides which parts of the operator state to spill and how to store the spilled state on disk. The restoring phase is executed after the operator has processed all the input. It reads the spilled state from disk and merges it with un-spilled state in memory to produce the result. Different operators use different spilling algorithms. This document discusses the algorithms used by Hash Aggregation, Order By, and Hash Join operators.
Spilling Framework¶
Spilling in Velox consists of a spilling framework and a set of spillable operators built on top of it. The spilling framework provides the common spilling functions which includes spill data collection, partition, sort, serialization/deserialization and the storage read and write. Each spillable operator uses these functions to implement its own spilling algorithm.
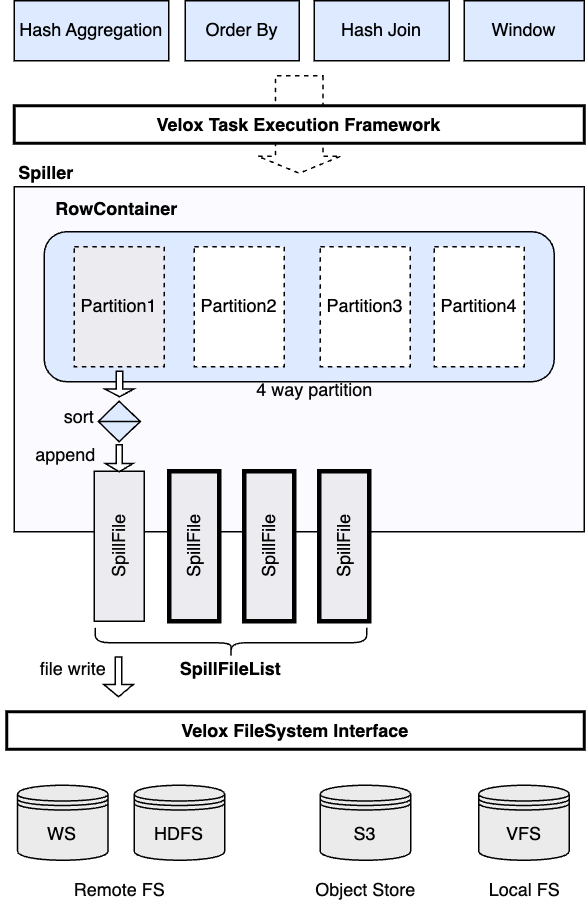
Spill Objects¶
The spilling framework consists of the following major software objects:
Spiller¶
The Spiller object provides the spilling functions for all the operators and helps them manage their spilled state on disk. There is one Spiller object created for each operator. The Spiller object takes a row container object on construction (except hash probe operator which doesn’t buffer input and directly writes spilling rows to disk). The row container is a row-wise in-memory data store owned by the operator to store its in-memory state that could be spilled to disk when there is no memory available. For example, the row container of a hash aggregation operator stores the intermediate aggregation state with one row per each group (a unique combination of the values of the grouping keys). When the operator needs to spill, the Spiller scans all the rows in the row container and calculates each row’s partition number, decides which partitions need to spill, and then write them out as a list of files. The Spiller can sort the data before writing to disk. If sorting is enabled, the Spiller creates a separate file for each sorted run. On restore, the Spiller reads back the spilled data to restore the in-memory state. If sorting is enabled, it creates a merge sort reader to read the sorted data. This functionality is used by Hash Aggregation and Order By operators.
Spiller implements the following major functions:
Spill data partition: when spilling, we only want to spill a minimum amount of data to disk and keep the rest of the operator state in-memory. The Spiller divides the rows in the row container into a number partitions and spills only some of them as needed. This technique reduces IO costs and speeds up the restore procedure. Un-spilled partitions are processed using regular (in-memory) fast execution path. Each spilled partition has a separate set of files on disk. Spilled partitions are restored and processed one at a time. A set of columns (partition columns) to compute the partition numbers are specified by the operator based on the spilling algorithm. Hash aggregation operator partitions data using grouping keys to ensure all rows from the same group are spilled and restored together (as part of the same partition).
Select partitions to spill: when spilling kicks in, it selects partitions with the most data. It then sticks with those partitions if they have sufficient memory to free up. The spillable data is measured as the memory bytes occupied by the rows in the row container. Operators that use sorted spilling should avoid spilling partitions with little amount of data even if these partitions have been spilled previously. Sorted spill creates a new file for each sorted run and doesn’t support appending data to an existing file. Non-sorted spill can append new data to existing files as needed.
Sort data while spilling: operators that use sorted spill combine spill files with in-memory data using sort merge algorithm. The in-memory data will also be sorted as one of the sorted runs. The Spiller sorts the rows by partition columns with a set of comparison flags specified by the operator. For example, the order by operator needs to ensure the sorted runs follow the same sort order as specified by the query plan node.
Spill data io: the Spiller handles the interaction with the storage system through SpillFileList and SpillFile objects as discussed below. It manages the lifecycle of a spill file from creation, write, read and deletion. The spill writes are offloaded to a dedicated IO executor and each spill partition write is a thread execution unit. The spill reads are executed in the driver executor. Both read and write are synchronous IO operations.
The Spiller provides the following spilling APIs for operators to use:
Spill APIs¶
spill with targets: the operator specifies the number of rows and bytes to spill as the target. The Spiller selects a number of partitions to spill to meet the target. Spilling runs internally and returns after the spilling is complete. The spilling process is not controlled by the operator but it can check which partitions have been spilled and how much data has been spilled through spill stats API.
void Spiller::spill(uint64_t targetRows, uint64_t targetBytes);
SpillPartitionNumSet Spiller::spilledPartitionSet() const;
Stats Spiller::stats() const;
spill partitions: the operator specifies the partitions to spill and the Spiller spills all the rows from the specified partitions to disk. The spilling process is controlled by the operator in this case. It is used by the hash build operator to run spilling on all the build operators in coordination. When spilling gets triggered, one of the operators is selected to run the spill on all the operators (also called a group spill in discussion below). It first collects spillable stats from all the operators through Spiller::fillSpillRuns() and then selects a number of partitions to spill.
void Spiller::spill(const SpillPartitionNumSet& partitions);
void Spiller::fillSpillRuns(std::vector<SpillableStats>& statsList);
spill vector: the operator spills a row vector to a specified partition. The Spiller directly appends the row vector to the currently open spill file from that partition. The spilling process is also controlled by the operator. It is used for spilling by the hash join. Both hash build and hash probe operators spill input rows to disk if the corresponding partition has been spilled. For the hash build operator, if a partition has been spilled, then all the input rows from that partition have to spill as we can’t build a hash table with a subset of rows from that partition to join. For the hash probe operator, it itself is not spillable but it needs to spill the input rows if the associated partition has been spilled by the hash build. We discuss this further in the hash join spilling section.
void Spiller::spill(uint32_t partition, const RowVectorPtr& spillVector);
Restore APIs¶
sorted spill restore: Used by order by and hash aggregation operators. The operator first calls Spiller::finishSpill() to mark the completion of spilling. The Spiller collects rows from unspilled partitions and returns these to the operator. The operator processes the unspilled partitions, emits the results and frees up space in the RowContainer. Then, it loads spilled partitions one at a time. It calls SpillPartition::createOrderedReader() for each spilled partition to create a sorted reader to restore the spilled partition state.
void Spiller::finishSpill(SpillPartitionSet& partitionSet);
std::unique_ptr<TreeOfLosers<SpillMergeStream>>
SpillPartition::createOrderedReader();
unsorted spill restore: Used by hash build and hash probe operators. The operator first calls Spiller::finishSpill() to mark the completion of spilling. The Spiller collects metadata for the spilled partitioned and returns these to the operator. The operator processes the unspilled partitions, and emits the results and frees up space in the RowContainer. Then, it loads spilled partitions one at a time. It calls SpillPartition::createReader() for each spilled partition to create unsorted reader to restore the spilled partition state.
void Spiller::finishSpill(SpillPartitionSet& partitionSet);
std::unique_ptr<UnorderedStreamReader<BatchStream>>
SpillPartition::createReader();
SpillFileList and SpillFile¶
SpillFileList object manages spill files for a single partition. Each spill file is managed by one SpillFile object which provides the low level io operations with the storage system through Velox file system interface. On the spill path, the SpillFileList object takes a row vector as input, creates a VectorStreamGroup to serialize the row vector and writes out the serialized byte stream into the currently opened spill file through the corresponding SpillFile object. The SpillFileList object starts a new spill file if the current file grows beyond the target file size. On the restore path, the SpillFile object reads the serialized byte stream from the underlying storage system, and uses VectorStreamGroup to deserialize the byte stream into row vectors.
Spill Triggers¶
Spilling will be integrated with the Velox memory management system as a way to reclaim memory when the system lacks memory. Whenever an operator can’t allocate or reserve new memory, the memory arbitrator will select a number of Velox tasks to shrink their memory usage to satisfy the new memory allocation or reservation request. Each selected task will try to reclaim memory from its spillable operators. The latter in turn frees up memory by spilling out (part) of its memory state to disk. The integration of spilling with the memory management system is under development.
Spill Parameters¶
Spill File Size¶
Given the same amount of spill data, the spill file size determines the number of spill files on disk. On the one hand, we should avoid generating too many small spill files as it might overload the metadata service of the storage system. On the other hand, we also want a sufficient number of spill files to parallelize the restore work. For example, to build a hash table from a spilled partition, we can parallelize the build work among multiple hash build operators by assigning each of them a shard of spill files. There are two configuration properties to control.
max_spill_file_size sets the maximum spill file size limit. For unsorted spill, as we continuously append to the same spill file so this helps to prevent a spill file from growing too big. For sorted spill, each file stores only one sorted run of data, hence, the spill file size is the minimum of spillable data size and this configuration limit.
min_spill_run_size sets the minimum data size used by sorted spill to select partitions for spilling. Each sorted spill file can only store one sorted run of data. Spiller tries to spill from the same set of partitions if possible. By having this configuration limit, we can avoid spilling from partitions which have small amount of data, to avoid generating too many small spill files.
Both configuration properties can be tuned based on IO characteristics of the underlying storage system. We don’t expect they needs too much tuning in practice.
Spill Target Size¶
The spill target size determines how much data to spill each time. If too small, spilling interrupts operator execution frequently and generates lots of small files. If too large, operator execution slows down by spilling lots of data to disk. Configuration property spillable_reservation_growth_pct sets the spill target size as a factor of the query memory limit. We might need to tune this parameter a bit in practice to see its impact on performance.
Spill Compression¶
To reduce the spill file size when the size might exceed the disk space, we can enable spill compression. The Spiller compresses the serialized byte stream before writing it to disk. Configuration property spill_compression_codec sets the compression codec to use.
Data Storage¶
The spilling just needs the underlying storage system to store a number of named streamed bytes. It may or may not need the namespace support. If the storage system supports namespace, we could store the spilled files from a query in one directory and delete them all by one directory deletion at the Spark Driver for Sapphire or Presto Coordinator for Prestissmo when a query finishes. If storage system doesn’t support namespace hierarchy, Velox deletes files one by one. When a system crashes, it is likely that some spill files are left on the storage system so we need some sort of garbage collection support. For storage systems that support time to live (TTL), we can leverage that feature to implement the spill file garbage collection. If not, we might need to build a lightweight garbage collection (GC) service running out of band.
std::string makeOperatorSpillPath(
const std::string& spillPath,
const std::string& taskId,
int driverId,
int32_t operatorId);
Spilling Algorithm¶
Hash Aggregation¶
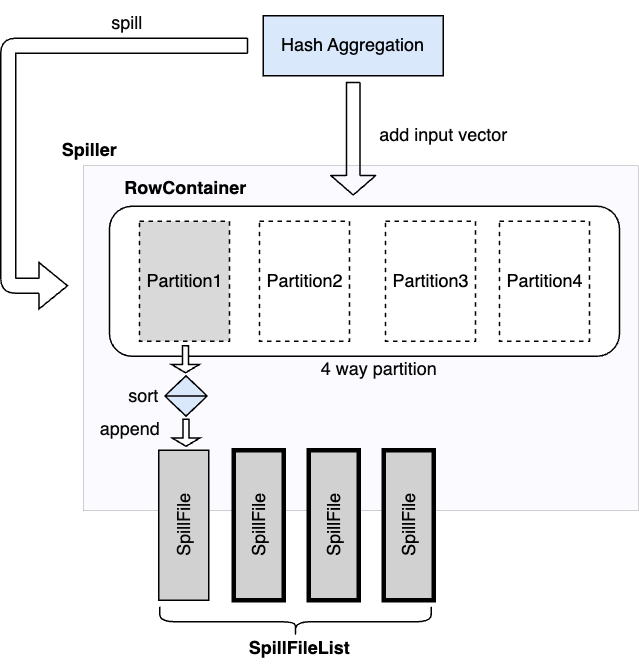
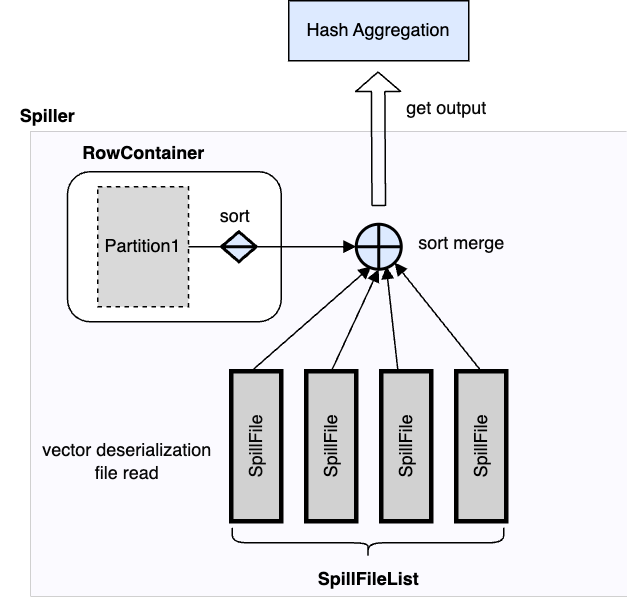
The hash aggregation operator stores the intermediate aggregation state in a hash table with one table entry per group. When spilling is triggered, the operator’s Spiller object scans all the rows in the row container to select a set of partitions with the most data that collectively meet the spill target. The table entries of the spilled rows are removed from the hash table. After the spilling completes, the operator continues processing the input until the next spilling gets triggered which repeats process above. The Spiller prefers to spill the same partitions again if they have sufficient amount of spillable data. This technique limits spilling to a subset of the aggregation state if possible.
After processing all the input, the hash aggregation operator produces the result by merging the in-memory and on-disk states. For each spilled partition, the operator sorts all rows left in the row container as a single sorted run. Each spill file on disk is also a sorted run. Then the operator creates a sort merge reader with all the sorted runs to merge the intermediate states with the same grouping keys into one final aggregation state for output. The intermediate state of a group can be spilled multiple times during the operator’s execution. Note that the sort is based on the grouping keys.
OrderBy¶
The order by operator stores all the input rows in a row container and sorts them all after it has received all the inputs. When spilling gets triggered, the Spiller collects a sufficient number of rows to spill to satisfy the spill target. Unlike the hash aggregation spilling, we don’t partition the rows for spilling as the order by operator needs to generate the total order on all the input rows for output. After the spilling completes, the operator continues the input processing until the next spill run gets triggered which repeats the process above.
After processing all the inputs, the order by operator first sorts any rows left in the row container as a single sorted run, and each spill file on disk is also a sorted run. Then the operator creates a single sort merge reader with all the sorted runs to produce the final sorted output. Note that the sort here needs to use the comparison options specified by the query plan node.
Hash Join¶
The hash join is implemented by hash build and hash probe two types of operators, and each belonging to a separate driver pipeline and the two pipelines are connected through a shared hash join bridge data structure. The hash build operators take the build side (or the right side in a join) inputs to build a hash table. After the build completes, one of the hash build operators sends the built table to all the hash probe operators through the shared hash join bridge. The hash probe operator takes the probe side (or the left side of a join) input to join with the hash table with one batch at a time.
The hash probe operator holds at most one batch of probe input rows in memory at a time so the hash probe processing doesn’t use too much memory. The hash build operators might use a large amount of memory to build the hash table and keep it in the memory for the entire hash join processing. Similar to the order by processing, each hash build operator stores the build side inputs into a row container, and after all the hash build operators have processed the inputs, one of them builds a single aggregated hash table with the rows collected from all the hash build operators.
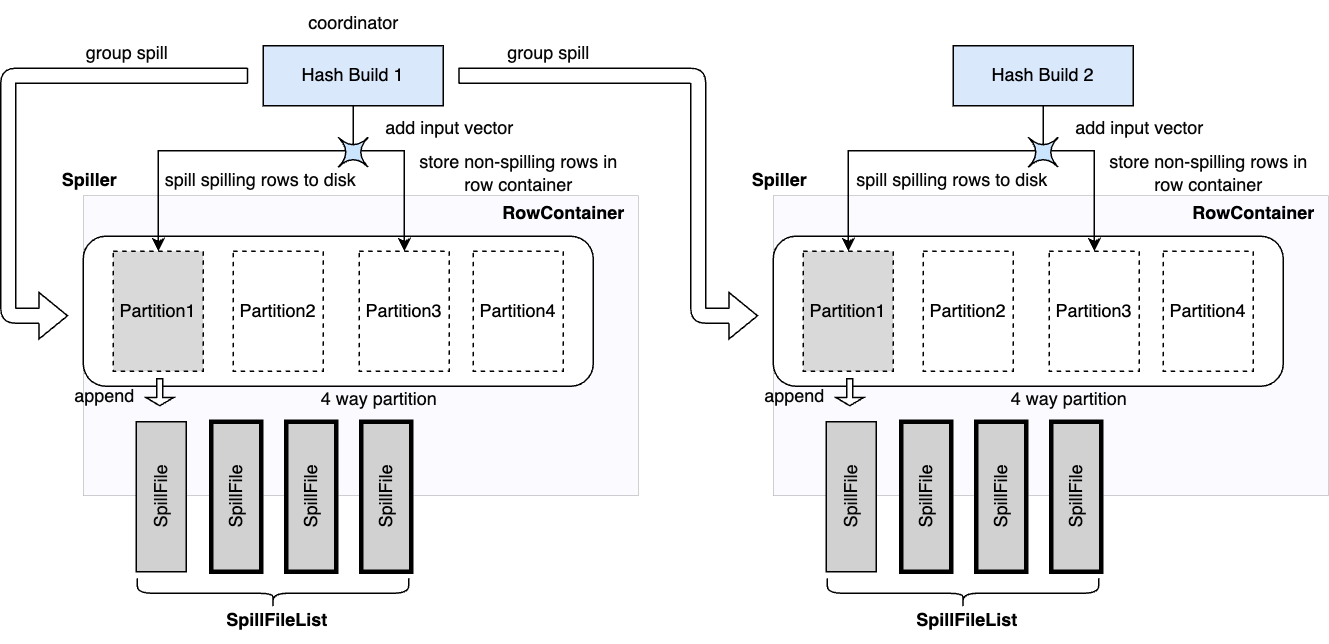
To prevent hash join from running out of memory, the hash build operators need to spill part of the build side inputs to disk if the row container grows too large during the processing. Hash build operators coordinate spilling with each other to ensure all operators spill the same set of partitions. If operators spill independently, it is possible to end up with all partitions being spilled. To build a hash table, we need all rows from one or more partitions. Unlike hash aggregation and order by, the hash join spilling is explicitly controlled by the hash build operators.
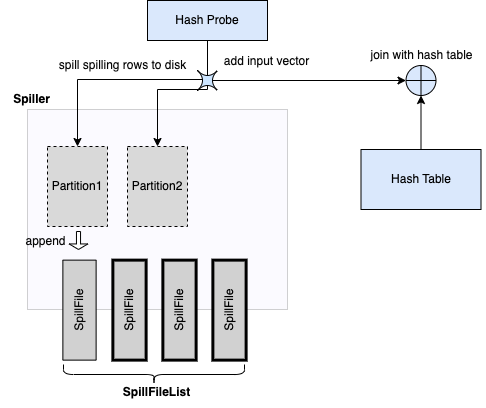
The hash probe operator itself is not spillable but we need to extend it to support the spilling happened at the build side. If the hash build operators have spilled partition N, then the hash probe operators have to spill all the input rows that belong to partition N as well, and only join the rest of probe inputs with the built table. Correspondingly, when the hash build operators build the hash table from partition N later, the hash probe operators need also read back the corresponding probe inputs from the spilled data on disk. Note that the hash join uses the join key columns as the partition columns, and unlike hash aggregation and order by, the hash join doesn’t need to sort the spill data.
If the build side is too big, we might run out of memory again when restoring one of the previously spilled partitions. If that happens, we perform recursive spilling which further splits a spilled partition (also called as parent partition below) into a number of subpartitions (also called child partition below) and runs through the process recursively. To support recursive spilling, we advance (or right shift) the partition bits used to calculate the spill partition number. Suppose the partition bit offset of a parent partition is 29th and we use 3 bits to do 8 way partitioning, the bit range of the parent partition is [29, 31], its child partition is [32, 35] on first level recursive spilling, the grand child partition is [36, 38] on the second level recursive spilling, and so on so forth.
Based on this, we can do a simple math on the maximum build table size (T) we can support with the following parameters: the query memory limit is M, the number of partition bits is N, the spilling level is L (1 for the initial spilling, 2 for the first level recursive spilling etc):
The following table gives the max supported table size at different spilling level, M = 1*GB*, N = 3:
Spill Level |
Total Partition Bits |
Max Table Size |
|---|---|---|
1 |
3 |
8 GB |
2 |
6 |
64 GB |
3 |
9 |
512 GB |
4 |
12 |
4 TB |
5 |
15 |
32 TB |
6 |
18 |
256 TB |
7 |
21 |
2 PB |
For production deployments, we recommend setting a limit for the max spilling level using max_spill_level configuration property.
The following gives a brief description of the hash build and probe workflows extended to support (recursive) spilling:
HashBuild¶
Process inputs from either build input source or the previously spilled data.
Try reserve memory for the new build inputs, if it fails or the aggregated hash build size (the memory used by the rows stored in row container) exceeds a limit, then send a spilling request to spill operator group.
Check and wait if there is a pending group spill request. If this operator is the last one reaching the spilling barrier, then it runs the group spill.
If there is any spilled partitions, then spill the corresponding input rows directly without buffering in the row container.
Store the non-spilled input rows into the row container for hash table build later.
After all the operators finish processing the build inputs, the last finished one builds the hash table from rows collected by all the operators, and sends the built table along with the optional spill metadata (if spilling has been triggered) to the hash probe operators through the hash join bridge.
Wait for the spill input to build the next hash table if there is any spill data needed to restore. Otherwise, the hash build operator just finishes. The hash probe operators pick a previously spilled partition to restore after finishing the join operation.
After receiving the spill input from the hash join bridge, the hash build operator resets the Spiller with advanced partition bits and creates an unordered reader to read build inputs from the spill files set in the spill input.
Go back to step 1 to repeat the next hash table build process.
Note that once we have memory arbitration support later, the spilling can also be triggered by the memory arbitrator on behalf of any failed memory allocation or reservation request from any operators. The memory arbitrator will stop the evicted tasks first before spilling so we might not need the coordinator support if the spilling is triggered in that case.
HashProbe¶
Wait for the next hash table to join from the hash join bridge plus additional spilling metadata if spilling gets involved: the table spill partition id (discussed below) which identifies the associated spill partition if the table is built from a previously spilled partition and the child spill partition id set which is set to the ids of the partitions that have been spilled while building the hash table.
Create an unordered reader to read probe inputs from the previously spilled data if the table spill partition id is set. The table spill partition id specifies the corresponding spilled probe inputs to read from disk.
Process inputs from either probe input source or the previously spilled probe inputs.
Spill input rows to disk if the corresponding partitions have been spilled by the build side which are identified by child spill partition id set if not empty.
Join the non-spilled probe input rows with the hash table and produce the result.
After all the operators finish processing the inputs, if there is no spilled data needed to restore, then all the hash probe operators finish. Otherwise, the last finished operator signals completion of processing to the bridge. The bridge then selects the next spilled partition to restore and wakes up the hash build operators.
Go back to step 1 to repeat the join process with the next built hash table.
Some hash probe optimizations are disabled if the spilling has been triggered by the hash build. For example, dynamic filtering is disabled because the complete set of join keys is not known.
Spilling not supported for null-aware anti-join type with filter because it requires to cross join null-key probe rows with all build-side rows for filter evaluation to check if the null-key probe rows can be added to output or not.
HashJoinBridge¶
The HashJoinBridge object includes the following extensions to support the spilling:
extends the existing setHashTable interface to take optional spilled partition metadata if spilling has been triggered while building the table.
adds probeFinished interface for the hash probe operator to set and notify the hash build operators of the spill input to build the next hash table.
adds spillInputOrFuture interface for the hash build operator to wait for the spill input to build the next hash table.
Internally, the object maintains all the spill partitions remaining to restore in an ordered map and restore the next spill partition from the beginning of the map. To ensure the child partitions are restored first, we add the SpillPartitionId type as the key in the map to identify a spill partition which consists of partition bit offset and the partition number. The partition with higher bit offset is placed ahead of the one with lower bit offset. If the partition bit offset ties, then partition with a lower partition number goes first.
To parallelize the hash table build from the spilled partition, the hash join bridge will split the spill partition files among the hash build operators with each one having an equally-sized shard to restore.
Reclaim Across Memory Resources¶
The spilling algorithms above describe how a spillable operator releases memory by serializing in-memory state to disk. With custom memory resources, the reclaim path is not restricted to disk. The per-query reclaimer attached to a custom root pool can move data into a sibling tier — for example, copying buffers out of a device memory pool into a pinned-host pool, or evicting cold pages from a CXL-attached pool into a local DRAM pool. MemoryPool::reclaim on a custom pool dispatches to the reclaimer the reclaimerFactory produced; what the reclaimer does is up to the extension.
A chain of reclaimers — for instance, hash table on CPU DRAM → CXL on first reclaim → disk on second reclaim — is built by composing reclaimers across resources. Each link is an independent reclaim decision made by the arbitrator of the pool that ran short. The framework does not coordinate the chain; the extension picks the topology by deciding which sibling each reclaimer allocates into. A reclaimer can reach a sibling pool by closure-capturing the sibling at the resource’s reclaimerFactory.
Example: CXL-Backed Hash Aggregation¶
The reclaim path above is meaningful when the custom resource exposes a tier with different access properties from CPU DRAM. CXL-attached memory is one such tier: it is slower than local DRAM but exposed to the CPU as part of the coherent virtual address space — host code can dereference a CXL pointer directly, with no copy back to DRAM required.
A CXL extension takes advantage of this by registering a CXL custom resource and installing a CXL-aware HashAggregation through DriverAdapter. The adapter is the standard mechanism Velox uses to swap in alternate operator implementations (also used by the cuDF and Wave extensions); see DriverAdapter in velox/exec/Driver.h. The CXL-backed operator preserves the public HashAggregation contract while changing the reclaim policy:
First reclaim trigger (DRAM is tight). Like the default operator, the CXL-backed HashAggregation selects a spill target — the set of partitions with the most data — and processes the corresponding rows in its DRAM row container. Unlike the default operator, it copies each row into the CXL custom pool and pointer-swizzles the corresponding hash-table bucket entries to the new CXL addresses, rather than clearing them. The swizzle has the same cost shape as the default operator’s hash-table entry removal — a ProbeState walk per row to find each bucket slot — but with greater benefit: because CXL memory is coherent with the CPU address space, probe and finalize logic continue to read the relocated entries directly with no restore step.
CXL pool fills. Subsequent reclaim triggers continue moving partitions from DRAM into CXL until the CXL custom pool’s arbitrator decides it is out of capacity. At that point arbitration on the CXL pool calls MemoryPool::reclaim on the CXL root pool, which dispatches to the reclaimer the resource’s reclaimerFactory produced.
Second reclaim — CXL into disk. The reclaimer behaves like the default HashAggregation spill path, just sourced from CXL instead of DRAM. It scans the partitions stored in CXL, serializes them through the standard Spiller onto disk, and notifies the operator to remove the corresponding entries from the hash table. Removal happens here, not in step 1, because this is the first point at which the entries are no longer directly addressable.
Finalize. After receiving all input the operator produces results by merging three sources for each partition: rows still in the DRAM row container, rows that live in CXL (read directly with no restore), and rows on disk (read back through the standard Spiller restore path). For partitions that never made it past step 1 the merge degenerates to “DRAM + CXL”; for partitions reclaimed in step 3 it degenerates to “DRAM + disk” — the same shape as the default HashAggregation algorithm.
The CXL pool is registered like any other custom resource on the
CustomMemoryResourceRegistry. The resource carries the reclaimer factory
the caller uses to materialize per-query reclaimers for pools tagged
"cxl":
The arbitrator passed here governs only the CXL pool’s capacity. The framework never makes the decision to move bytes from DRAM to CXL on its own; the trigger and the reclaim policy come from the extension. Step 1 can be driven as follows: the operator calls MemoryPool::setReclaimer on its DRAM-side row pool with a custom reclaimer that moves rows to CXL. The default MemoryArbitrator on MemoryManager triggers reclaim normally when the query is under capacity pressure; the propagation reaches the installed reclaimer, which redirects the move to CXL instead of disk. See DramReclaimer in velox/common/memory/tests/CustomMemoryEmulationTest.cpp for a worked example.
The CXL → disk hop is analogous: install a reclaimer on the CXL root pool through the resource’s reclaimerFactory, and let the CXL pool’s arbitrator trigger it when the CXL budget is exhausted. This way, we can achieve cross-resource arbitration.
Future Work¶
Memory Arbitration¶
Introduce memory arbitration logic to choose operators to reclaim memory from running queries when any operator fails to allocate or reserve memory. The memory arbitrator can reclaim memory from both spillable and some non-spillbale operators which store data in the RowContainer. For spillable operator, we need to add arena compaction to free up unused memory chunks. For non-spillable operator such as partial aggregation, the memory arbitrator can reclaim memory by requesting partial aggregation operator to flush its state to the downstream query stage. The memory arbitration logic will allow queries to complete successfully using limited amounts of memory and enable dynamic memory sharing between concurrent queries to improve overall memory efficiency.
Runtime Statistics Collection¶
Add the following RuntimeMetric stats to measure the spilling execution internals to help performance analysis in production:
Spill data size: spill bytes, spill rows, spill partitions, spill files and spill file size distribution. We can tune the spilling parameters to see the impact on these stats and the resulting performance changes.
Spill execution time: how much time an operator spends on spilling which breaks down into the following parts:
spill data scan: the row iteration and the partition number calculation times. If the partition number calculation turns out to use a significant portion of CPU time, we could optimize this step by caching the calculated partition number along with the row in the row container.
spill data sort: the spill data sort time.
spill data conversion: the time to convert rows in the row container into a vector for spill.
spill data serialization: serialization time of the converted vector into a byte stream for spill write.
spill data deserialization: deserialization of a byte stream back into the row vector for spill read.
spill file write: the spill file write time. It can be tuned by adjusting the spill executor pool size as well as considering the fine-grained parallel writes.
spill file read: the spill file read time. It can be optimized by read ahead.
Spilling Extension¶
Add spilling support for window operator.